

1. [10%] Please describe the steps involved in developing and executing assembly language program?
參考解答:
(1) Write an assembly language program.
(2) The assembler translates assembly language statements to their binary equivalents (object code).
(3) Separately assembled modules are combined into one single load module, by the linker.
(4) The program loader copies the program into the computer’s main memory, and at execution time, program execution begins.
2. [10%] Please write the MIPS code to compute the mathematic formula a \times b + 3c – 10.
參考解答:Assume that the values of variables a, b and c are contained in registers $s0, $s1, and $2, respectively, and the computation result will be included in registers $t0 and is smaller than 32 bit binary number can represent.
mul $t0, $s0, $s1
sll $t1, $s2, 1
add $t1, $t1, $s2
add $t0, $t0, $t1
addi $t0, $t0, -103.
(a) [5%] If processor A has a higher clock rate than processor B, and processor A also has a higher MIPS rating than processor B, explain whether processor A will always executes faster than processor B.
(b) [5%] Computer A has an overall CPI of 1.5 and can be run at a clock rate of 700MHz. Computer B has a CPI of 2.0 and can be run at a clock rate of 650MHz. We have a particular program to run and this program has exactly 120,000 instructions when compiled for computer A. How many instructions would the program need to have when compiled for Computer B if we want the two computers to have exactly the same execution time for this program?
參考解答:
(a) We cannot differentiate which machine is faster from the measure of MIPS before the capabilities of the ISA of these two machines are given.
(b) Suppose \text{IC}_B represents instruction count for Computer B. Execution time for Computer A = Execution time for Computer B \rightarrow (120000 \times 1.5)/700M = (\text{IC}_B \times 2)/650M \rightarrow \text{IC}_B = 83571.429 \approx 83571
4.
(a) [4%] What are the two characteristics of program memory accesses that caches exploit?
(b) [6%] What are three types of cache misses?
參考解答:
(a)
Temporal locality: If an item is referenced, it will tend to be referenced again soon.
Spatial locality: If an item is referenced, items whose addresses are close by will tend to be referenced soon.
(b)
Compulsory misses: a cache miss caused by the first access to a block that has never been in the cache.
Capacity misses: a cache miss that occurs because the cache even with fully associativity, can not contain all the blocks needed to satisfy the request.
Conflict misses: a cache miss that occurs in a set-associative or direct-mapped cache when multiple blocks compete for the same set.
5. [10%] Answer TRUE or FALSE for the following questions.
(a) A virtual cache access time is always faster than that of a physical cache.
(b) Both DRAM and SRAM must be refreshed periodically using a dummy read/write operation.
(c) High associativity in a cache reduces compulsory misses.
(d) A write-through cache typically requires less bus bandwidth than a write-back cache.
(e) Memory interleaving is a technique for reducing memory access time through increased bandwidth utilization of the data bus.
參考解答:(a) T, (b) F, (c) F, (d) F, (e) T.
6. [9%] Answer TRUE or FALSE for the following questions. Please justify your answers.
(a) Multithreading is deemed as one of the necessary conditions of a deadlock. If the statement is true, please describe why it is a necessary condition. If it is false, please itemize all necessary conditions of a deadlock.
(b) A transaction is a series of read and write operations upon some data followed by a commit operation. If the series of operations in a transaction cannot be completed, the transaction must be aborted and the operations that did take place must be rolled back. The series of operations in a transaction must be treated as one indivisible operation to ensure the integrity of the data being updated. Is the statement true? If it is true, please specify the name of this requirement. If it is false, please describe why it is wrong.
(c) A RAID Level 1 organization achieves better performance for ‘read’ requests than a RAID Level 0 organization (with non-redundant striping of data). Is it true? Justify your answer.
參考解答:(a) F, (b) T, (c) F.
7. [6%] Select the correct answers for the following questions.
(a) Which of the following scheduling algorithms could result in starvation:
1. First-come, first-served
2. Shortest job first
3. Round robin
4. Priority
(b) Which of the following states are valid states in Linux, i.e., the possible STAT indicated in the ps command:
1. Running or runnable
2. Stopped
3. Interruptible sleep
4. Calling
5. Initialize
參考解答:(a) 2,4 (b) 1,2,3
8. [10%] The following implementation of a semaphore is risky. Please describe why it could fail in a multithreaded application. What kind of system supports is required to implement a thread-safe semaphore?
class Semaphore {
int available; //in shared memory
public:
Semaphore() {available=1;}
int acquire() {
while(available < 1) {
sleep(1);
}
--available;
}
int release() {++available;}
};參考解答:There is no mutual exclusion for the variable available.
9. [10%] Consider the following set of jobs to be scheduled for execution on a single CPU system.
| Job | Arrival Time | Size (msec) | Priority |
| J1 | 0 | 10 | 2 (Silver) |
| J2 | 2 | 8 | 1 (Gold) |
| J3 | 3 | 3 | 3 (Bronze) |
| J4 | 10 | 4 | 2 (Silver) |
| J5 | 12 | 1 | 3 (Bronze) |
| J6 | 15 | 4 | 1 (Gold) |
(a) Draw a Gantt chart showing FCFS scheduling for these jobs.
(b) Consider FCFS, SJF, and non-preemptive PRIORITY scheduling algorithms. Which of the foregoing scheduling policies provides the lowest waiting time for this set of jobs? What is the average waiting time with this policy?
參考解答:
(a)
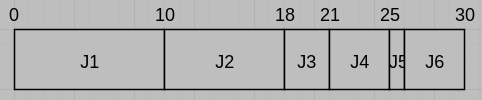
(b) (1) SJF (2) 5.8ms
10. [10%] A system has four processes and five resources which can be allocated. The current allocation and maximum needs are given below. To ensure it is a safe state, what is the smallest value of x according to the banker’s algorithm? Justify your answer.
圖片請看原檔
參考解答:x = 2
11. [5%] Consider a demand-paging system with a paging disk that has an average access and transfer time of 20 milliseconds. Addresses are translated through a page table in main memory, with an access time of 1 microsecond per access. Thus, each memory reference through the page table takes two accesses. To improve this time, we have added an associative memory that reduces access time to one memory reference, if the page-table entry is in the associative memory. Assume that 70 percent of the accesses are in the associative memory and that, of the remaining, 10 percent (or 3 percent of the total) cause page faults. What is the effective memory access time?
參考解答:EMAT = 601.3 \mu s
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



發佈留言