

1. (6%) What resources in a computer are used when a thread is created? How do they differ from those used when a process is created?
參考解答:OS will create a thread control block for it which uses some memory space.
2. (10%) Consider a variant of the round-robin (RR) CPU scheduling algorithm where the entries in the ready queue are pointers to the process control blocks (PCBs).
(a) What would be the effect of putting multiple pointers to the same process in the ready queue?
(b) What are the advantages and disadvantages of the scheme in (a)?
(c) How can the basic RR CPU scheduling algorithm be modified to achieve the same effect of the scheme in (a)?
參考解答:
(a) That process can use multiple time quantum before switching back to ready state.
(b)
Advantages: 在RR中可利用priority的參數化來避免某些process的turnaround time太長。
Disadvantages: 破壞了RR原本response time短的精神。
(c) Define multiple time quantums and high priority processes can have more time slice.
3. (8%) Suppose that a semaphore, mutex, which is initialized to 1, is used to solve the critical section problem. Consider the following three situations:
(S1) a process omits the signal(mutex);
(S2) a process omits the wait(mutex); and
(S3) a process omits both the signal(mutex) and wait(mutex).
(a) If (S1), or (S2), or (S3) is true, either (I)_____ is violated or (II)a _____ will occur. (Fill in each blank with one or two words in English.)
(b) In which situations, (S1), (S2), or (S3), will (I) happen?
(c) In which situations, (S1), (S2), or (S3), will (II) happen?
參考解答:
(a) (I) Mutual exclusion (II) Deadlock
(b) S2, S3.
(c) S1.
4. (4%) Name a common memory management technique (in English), other than compaction, that can be used to solve the problem of external fragmentation.
參考解答:Paging
5. (5%) Consider a demand-paging memory management system that used the additional-reference-bits algorithm for page replacement. Let $b$ be the 8-bit byte that we keep for a page $P.$ Let $(t_1,t_2,t_3,…)$ be the sequence of times at which $b$ is updated. Suppose that the decimal value of $b$ after the update at time $t_{20}$ is 147. Assume that the numbers of references to the page $P$ at the time intervals $(t_{20},t_{21}),(t_{21},t_{22}),(t_{22},t_{23}),(t_{23},t_{24}),(t_{24},t_{25}),(t_{25},t_{26}),(t_{26},t_{27}),(t_{27},t_{28})$ are, respectively, 0, 1, 2, 0, 3, 0, 4, 2. What is the decimal value of $b$ after the update at $t_{23}?$ Detailed explanation is necessary.
參考解答:210
6. (4%) Describe how UNIX uses inode structure to allocate disk spaces, and why it can be beneficial for small files and large files.
參考解答:In UNIX file system, they use inode structure where the first 12 entries are pointed directly to the data blocks and the next 3 entries are 1-level indirect, 2-level indirect and 3-level indirect, respectively. Where 1-level indirect entry points to another block with full of entries and then is the data block. So UNIX inode structure can easily support small files and large files at the same time.
7. (4%) Explain how RAID can improve the reliability and performance of secondary storage systems.
參考解答:RAID is a data storage virtualization technology that combines multiple physical disk drive components into one or more logical units for the purposes of data redundancy, performance improvement, or both.
8. (9%) There are many approaches to improve the performance of I/O, for example, using Direct Memory Access (DMA). Describe how DMA works to accelerate the I/O operations, and list three other approches to improve the I/O performance.
參考解答:
With DMA, the CPU first initiates the transfer, then it does other operations while the transfer is in progress, and it finally receives an interrupt from the DMA controller (DMAC) when the operation is done. This feature is useful at any time that the CPU cannot keep up with the rate of data transfer, or when the CPU needs to perform work while waiting for a relatively slow I/O data transfer.
Other approches: (1) Proper scheduling method (2) Understand the locality so we can make accesses sequential (3) Advanced hardware (ex: Disk to SSD)
9. (10%) In computers, floating-point numbers are expressed as the signed bit, exponent and fraction field. The bits of the fraction present a number between 0 and 1. Assume that the floating point numbers are 32 bits, with a bias of 127. Let $x = 0.3125$ and $y = -0.09375$ (in decimal).
(a) Show the floating-point number presentation of x and y using hexadecimal representation.
(b) Show the floating-point number presentation of $x \times y$ using hexadecimal representation.
參考解答:(a) x = 0x3EA00000, y = 0xBDC00000. (b) 0xBCF00000
10. (6%) Two n-bit inputs A[i] and B[i] are combined by the two’s-complement subtraction (A-B) with the subtraction result denoted as Sub[i]. The most significant bit n-1 is the signed bit. Bor(n-2) denote the borrow from bit n-2 to bit n-3. Indicate whether each of the following conditions is a valid test for two’s complement overflow. (The condition must be true if and only if there is overflow.)
Answer True or False for the following cases.
(a) A(n-1) XOR B(n-1) = 1 and Sub(n-1) = 1
(b) A(n-1) XOR B(n-1) = Bor(n-2)
(c) A(n-1) XOR B(n-1) = 1 and Sub(n-1) $\neq$ A(n-1)
參考解答:(a) F (b) T (c) T
11. (6%) Assume a processor has a base CPI of 1.4, running at a clock rate of 4GHz. The access time of the main memory is 50ns, including all the miss handling. Suppose the miss rate per instruction at the primary cache is 4%. What will be the speedup after adding a secondary cache with a 5ns access time for either a hit or a miss? Assume that the miss rate to main memory can be reduced to 0.2%.
參考解答:$\dfrac{9.4}{2.6} \approx 3.6$
12. (4%) Consider a system with the virtual memory address of 32 bits, and the physical address of 28 bits. The page size is 2KB. Each page table entry is 4 bytes in size.
(a) How many bits are in the page offset portion of the virtual address?
(b) What is the total page table size?
參考解答:(a) 11 bits (b) 8MB
13. (9%) A specific memory organization has the following memory access times:
(i) 1 memory bus clock cycle to send the address;
(ii) 10 memory bus clock cycle for each DRAM access initiated;
(iii) 1 memory bus clock cycle to send a word of data.
Assume that a cache block has eight words. Each word has four bytes.
(a) Increase the width of the memory organization (as well as the bus) can increase the memory bandwidth. Determine the smallest width of the memory organization in terms of bytes, such that the bandwidth (number of bytes transferred per bus clock cycles) for a single miss exceeds 1.2 bytes/cycle.
(b) Instead of increasing the width of memory, the interleaved memory organization can be used utilizing the advantage of multiple banks, each with one word wide. What is the bandwidth speedup of the interleaving scheme as compared with the original one-word-wide memory?
參考解答:(a) 16 bytes (b) $\dfrac{89}{29} \approx 3.06$
14. (15%) The beq instruction of MIPS will cause the processor to branch to execute from a target address if the contents of the two specified registers are equal:
beq $rs, $rt, Target # branch to Target if $rs == $rtIt uses the I-type format shown below, where Opcode is 6-bit wide, rs and rt are 5-bit wide, and Immediate has 16 bits with the leftmost bit as the sign bit.
$$Opcode | rs | rt | Immediate$$
The target address of beq is calculated as PC + (Immediate * 4). Consider the pipelined implementation of the MIPS processor shown in the next page and answer the following questions.
(a) Explain the purpose of the Adder in the ID stage.
(b) Explain the purpose of the Mux in the IF stage.
(c) Explain the purpose of the IF.Flush control signal.
(d) Suppose we have a branch target buffer, which uses PC as the input, can always predict correctly whether a branch will take, and supply the target address. Draw a diagram to explain how the IF stage may be modified. (Hint: Consider the outputs of the branch target buffer and what existing components may be removed.)
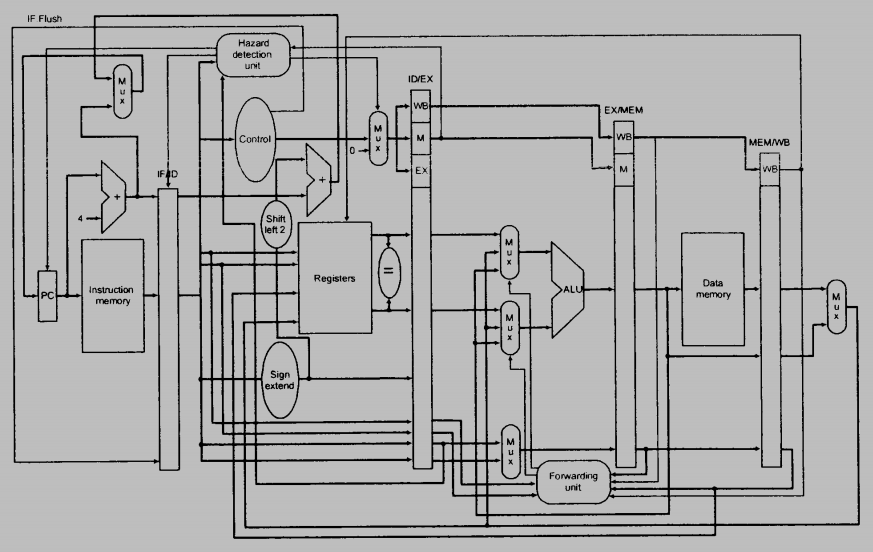
參考解答:
(a) The adder is used to compute branch target address.
(b) The Mux is used to select the branch target or PC+4 to update PC in the next clock cycle.
(c) The control IF.Flush is used to flush the wrong instruction in the IF stage.
(d) The multiplexor in front of the instruction seleccts the next instruction address from PC or BTB depend on the BHT state. If the BHT state indicates to guess not taken, the PC is applied to the instruction memory address input, otherwise the output of BTB is applied. The original multiplexor to selects between branch target and PC is removed. The following diagram only show the modification part in the IF stage.
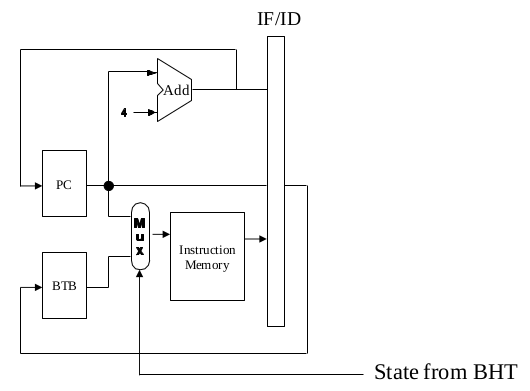
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



QQ
13.(b)為啥不是89/19
mt
這邊我是假設只有四個banks的interleaved memory所以是29,你如果假設有八個banks那就是19。
QWER
想請問10.詳解,感恩您
mt
這題可以用4-bit的二補數來測試,例如:4 – (-5) = 9(有overflow)。
0100
-1011
—–
1001
然後可以觀察到A(3) xor B(3) = 1,Sub(3) = -1,Bor(2) = 1。
就可以得到答案~
COVID退散
想請問第5題要如何計算?
還有第12的b為什麼是8MB?
感恩好人一生平安!!
mt
第五題是用additional-reference-bits algorithm,所以如果在區間內有reference到則整個reference bits往右shift並在最左邊插入1,否則插入0。所以可以得到下面的過程:
t20: 10010011
t21: 01001001
t22: 10100100
t23: 11010010
最後再將11010010轉回10進制就好了。
12(b)則是因為32 – 11 = 21,所以總共需要2^21個page table entries,所以總大小為2^21 * 4 Bytes = 2^23 Bytes = 8MB。
good
想請問一下(3)-c
為何s1會造成deadlock
而s3卻不會呢
mt
S1的情況是只會call wait(mutex),所以在第一個wait後面的wait都沒有辦法通過,因為沒有call signal(mutex)。
S3則是兩個都不call那自然就不會有沒有辦法通過的問題。