

1. (6%) What is monolithic OS? What is microkernel OS? What is the kernel type of Apple’s iOS and Google’s Android? Please also give some examples to illustrate the services and/or functions found in a typical monolithic OS that may be external subsystems to a microkernel OS.
參考解答:
Monolithic OS: 將子系統整合成一大塊程序放進kernel的簡化架構,可以直接用sys. calls呼叫kernel services.
Microkernel OS: 移除kernel中不必要的service並將其移至user-level以sys. library方式提供。(ex: iOS and Android)
2. (4%) Please explain the concept of transaction atomicity.
參考解答:An atomic transaction is an indivisible and irreducible series of database operations such that either all occurs, or nothing occurs. A guarantee of atomicity prevents updates to the database occurring only partially, which can cause greater problems than rejecting the whole series outright.
3. (15%) A commonly used process model shows processes operating in the following five states: new, ready, waiting (or blocked), running, and exit, and the state transition events include admitted, interrupt (or timeout), completion, I/O (or event wait), dispatch and exit. But when considering the need of swapping, one suspend state and some state transition events will be newly added to the process model.
(a) Please draw a six-state process model and indicate the types of events that lead to each state transition.
(b) Please list all of the impossible transitions and explain why.
(c) For the six-state process model, please draw a queuing diagram. Note that the queue obeys a First-In, First-Out (FIFO) rule.
參考解答:
(a)
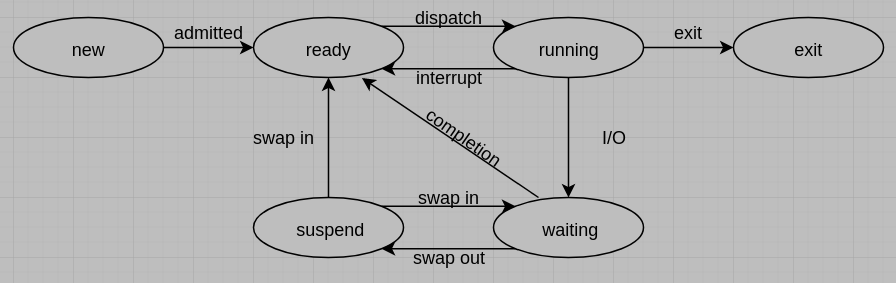
(b) 沒在diagram裡的路線都是impossible.(考試列出來)
(c)
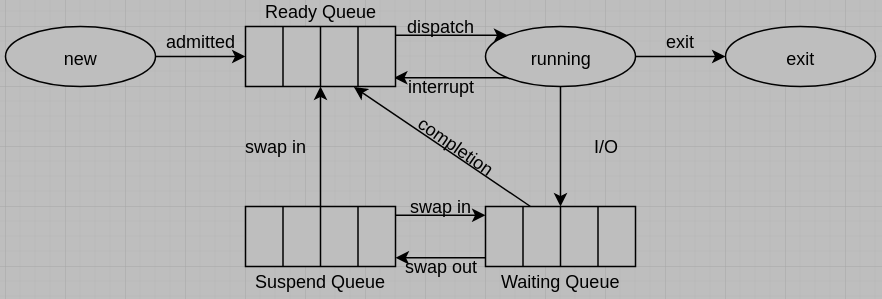
4. (5%) Consider a system consisting of m resources of the same type that are shared by n processes, each of which needs at most k resources. What is the minimum numbers of instances of resources to guarantee that the system is deadlock free? Explain your answer.
參考解答:If $nk < n+m,$ then the system is deadlock free.
5. (8%) A student in a compiler design course proposes to the professor a project of writing a compiler that will produce a list of page references that can be used to implement the optimal page replacement algorithm. Is this possible? Why or why not? Is there anything that could be done to improve paging efficiency at run time?
參考解答:It’s not possible to implement the optimal page replacement on hardware, since it requires future information. To improve paging efficiency, we can predict the needed pages and load it into memory at run time.
6. (6%) Is it possible for a process to have two working sets, one representing data and another representing code? Explain your answer.
參考解答:Yes, if we use the code frequently, we might want to split the working set for code and data.
7. (6%) Why might a system use interrupt-driven I/O to manage a single serial port, but polling I/O to manage a high performance network interface card?
參考解答:Interrupt-driven I/O are suitable for those I/O operations that will take time to complete, so if we use polling I/O for serial port, CPU won’t be able to execute others processes and lower the utilization. Polling I/O are suitable for those I/O operations that are done very fast, so if we use interrupt I/O or DMA to manage a high performance network, it may take most of the time doing context switch, which is not what we want.
8. (2%) What is the decimal value of “11110011”, a one-byte 2’s complement binary number?
參考解答:-13
9. (2%) For a color display using 8 bits for each of the primary colors (red, green, blue) per pixel and with a resolution of 1280*800 pixels, what should be the size (in bytes) of the frame buffer to store a frame?
參考解答:$1280 \times 800 \times 3 \text{ bytes } = 3072000 \text{ bytes}$
10. (4%) Determine the values of the labels ELSE and DONE of the following segment of instructions. Assume that the first instruction is loaded into memory location F0008000$_{hex}.$
slt $t2, $t0, $t0
bne $t2, $zero, ELSE
j DONE
ELSE: addi $t2, $t2, 2
DONE: ...參考解答:ELSE: F000800C$_{hex}$, DONE: F0008010$_{hex}$
11. (8%) Translate the following C code into MIPS assembly code:
f = A[B[2]] - 4;Assume the following register assigment: f in \$s1, the base address of A is at \$s2 and that of B is at \$s3.
參考解答:
lw $t0, 8($s3)
sll $t0, $t0, 2
add $t0, $t0, $s2
lw $s1, 0($t0)
addi $s1, $s1, -412. (8%) You are using a tool that performs machine code that is written for the MIPS ISA to code in a VLIW ISA. The VLIW ISA is identical to MIPS except that multiple instructions can be grouped together into one VLIW instruction. Up to N MIPS instructions can be grouped together (N is the machine width, which depends on the particular machine). The transformation tool can reorder MIPS instructions to fill VLIW instructions, as long as loads and stores are not reordered relative to each other (however, independent loads and stores can be placed in the same VLIW instruction). You give the tool the following MIPS program (we have numbered the instructions for reference below):
(01) lw $t0 <- 0($a0)
(02) lw $t2 <- 8($a0)
(03) lw $t1 <- 4($a0)
(04) add $t6 <- $t0, $t1
(05) lw $t3 <- 12($a0)
(06) sub $t7 <- $t1, $t2
(07) lw $t4 <- 16($a0)
(08) lw $t5 <- 20($a0)
(09) srlv $s2 <- $t6, $t7
(10) sub $s1 <- $t4, $t5
(11) add $s0 <- $t3, $t4
(12) sllv $s4 <- $t7, $s1
(13) srlv $s3 <- $t6, 4s0
(14) sllv $s5 <- $s0, $s1
(15) add $s6 <- $s3, $s4
(16) add $s7 <- $s4, $s6
(17) srlv $t0 <- $s6, $s7
(18) srlv $t1 <- $t0, $s7(a) Draw the dataflow graph of the program. Represent instructions as numbered nodes (01 – 18), and flow dependences as directed edges (arrows).
(b) When you run the tool with its settings targeted for a particular VLIW machine, you find that the resulting VLIW code has 9 VLIW instructions. What minimum value of N must the target VLIW machine have?
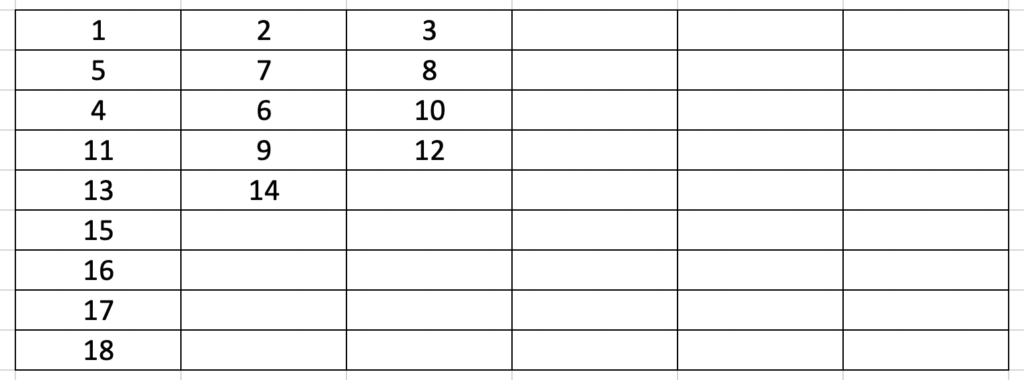
(c) Based on the code above and the minimum value of N in (b), write down the MIPS instruction numbers corresponding to each VLIW instruction in the table below. If there is more than one MIPS instruction that could be placed into a VLIW instruction, please choose the instruction that comes earliest in the original MIPS program.
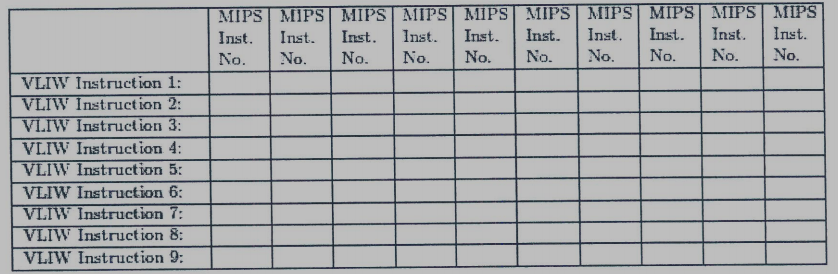
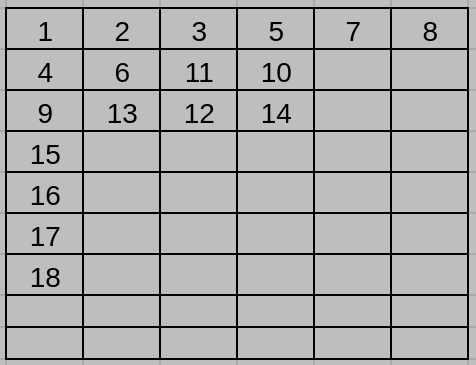
(d) You find that the code is still not fast enough when it runs on the VLIW machine, so you contact the VLIW machine vendor to buy a machine with a larger machine width N. What minimum value of N would yield the maximum possible performance (i.e., the fewest VLIW instructions), assuming that all MIPS instructions (and thus VLIW instructions) complete with the same fixed latency and assuming no cache misses?
(e) Write the MIPS instruction numbers corresponding to each VLIW instruction, for this optimal value of N. Again, as in part (c) above, pack instructions such that when more than one instruction can be placed in a given VLIW instruction, the instruction that comes first in the original MIPS code is chosen.
參考解答:
(a)
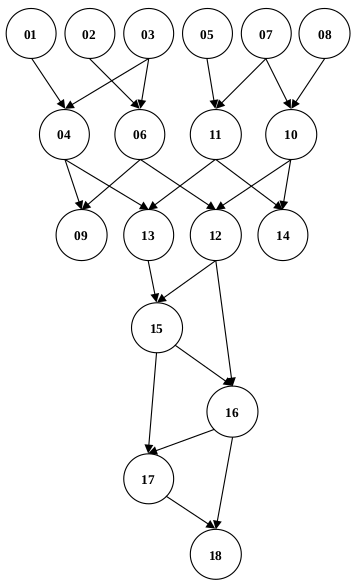
(b) The minimum value of N is 3
(c)
(d) The minimum value of N is 6 that would yield the maximum possible performance.
(e)
13. (9%) Fine-Grained Multithreading (FGMT): Consider a design “Machine I” with five pipeline stages: fetch, decode, execute, memory, and write back. Each stage takes 1 cycle. The instruction and data caches have 100% hit rates (i.e., there is never a stall for a cache miss). Branch directions and targets are resolved in the execute stage. The pipeline stalls when a branch is fetched, until the branch is resolved. Dependency check logic is implemented in the decode stage to detect flow dependences. The pipeline does not have any forwarding paths, so it must stall on detection of a flow dependence.
In order to avoid these stalls, we will consider modifying Machine I to use fine-grained multithreading.
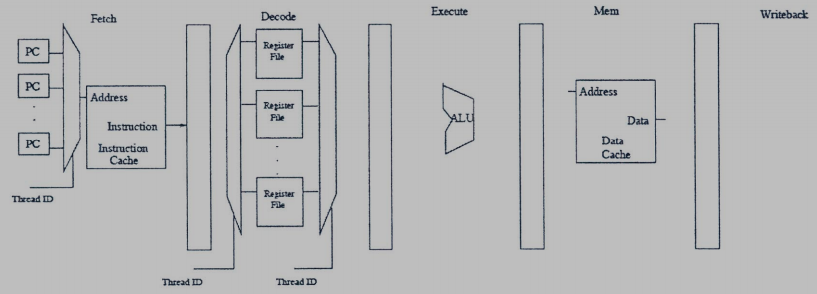
(a) In the five-stage pipeline of Machine I shown above, the machine’s designer first focuses on the branch stalls, and decides to use fine-grained multithreading to keep to pipeline busy no matter how many branch stall occur. What is the minimum number of threads required to achieve this? Why?
(b) The machine’s designer now decides to eliminate dependency-check logic and remove the need for flow-dependence stalls (while still avoiding branch stalls). How many threads are needed to ensure that no flow dependence ever occurs in the pipeline?
A rival designer is impressed by the throughput improvements and the reduction in complexity that FGMT brought to Machine I. This designer decides to implement FGMT on another machine, Machine II. Machine II is a pipelined machine with the following stages.
| Fetch | 1 stage |
| Decode | 1 stage |
| Execute | 8 stage |
| Memory | 2 stage |
| Writeback | 1 stage |
Assume everything else in Machine II is the same as in Machine I.
(c) Is the number of threads required to eliminate branch-related stalls in Machine II the same as in Machine I? If YES, why? If NO, how many threads are required?
(d) Now consider flow-dependence stalls. Does Machine II require the same minimum number of threads as Machine I to avoid the need for flow-dependence stalls? If YES, why? If NO, how many threads are required?
參考解答:
(a) 3 threads are required since branch directions and targets are resolved in the $3^{rd}$ (execution) stage.
(b) There are 3 stages from decode to writeback; hence 3 threads are required to remove the flow-dependence stalls. In addition, 3 threads are required to remove the branch stalls. So, there are total 3+3=6 threads are required.
(c) Yes. Since the branch directions and targets are still resolved in the $3^{rd}$ (execution) stage.
(d) No. There are 11 stages from decode to writeback; hence 11 threads are required to remove the flow-dependence stalls.
14. (8%) Assume you developed the next greatest memory technology, MagicRAM. A MagicRAM cell is non-volatile. The access latency of a MagicRAM cell is 2 times that of an SRAM cell but the same as that of a DRAM cell. The read/write energy of MagicRAM is similar to the read/write energy of DRAM. The cost of MagicRAM is similar to that of DRAM. MagicRAM has higher density than DRAM. MagicRAM has one shortcoming, however: a MagicRAM cell stops functioning after 2000 writes are performed to the cell.
(a) Is there an advantage of MagicRAM over DRAM? Why?
(b) Is there an advantage of MagicRAM over SRAM?
(c) Assume you have a system that has a 32KB L1 cache made of SRAM, a 8MB L2 cache made of SRAM, and 2GB main memory made of DRAM, as shown in Fig. 1.
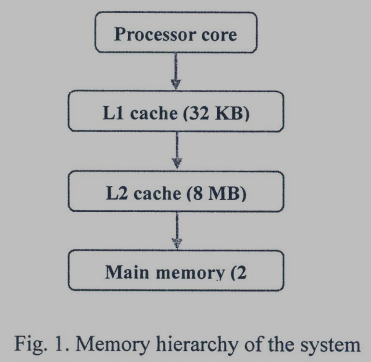
Assume you have complete design freedom and add structures to overcome the shortcoming of MagicRAM. You will be able to propose a way to reduce/overcome the shortcoming of MagicRAM (note that you can design the hierarchy in any way you like, but cannot change MagicRAM itself).
Does it make sense to add MagicRAM somewhere in this memory hierarchy, given that you can potentially reduce its shortcoming? If so, where would you place MagicRAM? If not, why not? Explain below clearly and methodically. Depict in a figure clearly and describe why you made this choice.
(d) Propose a way to reduce/overcome the shortcoming of MagicRAM by modifying the given memory hierarchy. Be clear in your explanations and illustrate with drawings to aid understanding.
參考解答:
(a) Yes. Since the MagicRAM has higher density than DRAM, the area and power consumption for the MagicRAM will be lower than that of the DRAM.
(b) Yes. Because the MagicRAM is non-volatile.
(c)
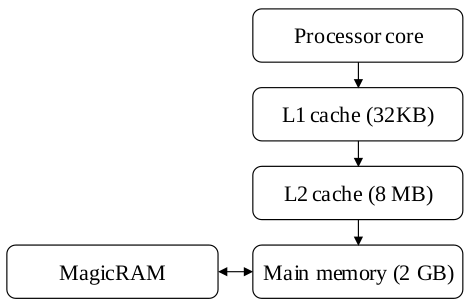
(d) We can put MagicRAM below or beside the Main Memory, treat it as a backup of the memory to reduce frequent write.
15. (9%) Consider the following three processors (X, Y, and Z) that are all of varying areas. Assume that the single-thread performance of a core increases with the square root of its area.
| Processor X | Processor Y | Processor Z |
| Core area = A | Core area = 4A | Core area = 16A |
(a) You are given a workload where S fraction of its work is serial and 1-S fraction of its work is in infinitely parallelizable. If executed on a die composed of 16 Processor X’s, what value of S would give a speedup of 4 over the performance of the workload on just one Processor X?
(b) Given a homogeneous die of area 16A, which of the three processors would you use on your die to achieve maximal speedup? What is that speedup over just a single Processor X? Assume the same workload as in part(a).
(c) Now you are given a heterogeneous processor of area 16A to run the above workload. The die consists of 1 Processor Y and 12 Processor X’s. When running the workload, all sequential parts of the program will be run on the larger core while all parallel parts of the program run exclusively on the smaller cores. What is the overall speedup achieved over a single Processor X?
(d) One of the programmers decides to optimize the given workload so that it has 10% of its work in serial sections and 90% of its work in parallel sections. Which configuration would you use to run the workload if given the choices between the processors from part(a), part(b), and part(c)? Please write down the speedups for the three configurations.
(e) Typically, for a realistic workload, the parallel fraction is not infinitely parallelizable. What are the three fundamental reasons?
參考解答:
(a) S = 0.2
(b) Speedup of processor Y = $\dfrac{1}{\frac{0.8}{8} + \frac{0.2}{2}} = 5.$ Speedup of processor Z = $\dfrac{1}{\frac{0.8}{4} + \frac{0.2}{4}} = 4.$ So, processor Y is better.
(c) $\dfrac{1}{\frac{0.8}{12} + \frac{0.2}{2}} = 6$
(d) Processor from part(c) is better.
(e) 1. Synchronization 2. Load imbalance 3. Resource contention
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



Jackson
請問12(c) 圖中 10 跟同期的 4 6 11 分開的原因是 ?
mt
(c)是based on (b)的minimum value of N = 3,也就是每一組VLIW指令不能超過三個MIPS指令,所以如果把4 6 10 11放一起就會超過三個指令。不過這題10跟11應該要交換,因為題目有說If there is more than one MIPS instruction that could be placed into a VLIW instruction, please choose the instruction that comes earliest in the original MIPS program.
Jackson
那請問 minimum value of N 是因為至少 lw 前三條指令要先執行完才能確保後面是能順利執行,所以 N = 3 嗎? 謝謝
mt
我們把(a)的圖建出來就可以知道哪些指令要先執行,(b)又問說target VLIW machine的每一個VLIW instruction最少只需要多少個MIPS instruction,然後因為總共只有9個VLIW instruction可以用,所以照著圖(a)畫就可以發現是3,如果VLIW instruction有18個可以用,那最小N就會是1~
Jackson
了解,因為最後4條一定分開執行,(18-4)/5 取上底 就是 3 感謝~
mt
不會~
QooQ
您好,想請問第13題的b好像有點怪怪的?題目說同時要避免data hazard造成的stall和branch造成的stall,個人認為最大thread數量應該是取max(hide data hazard需要的最小thread, hide branch stall需要的最小thread數量),而不是他們相加,感謝
mt
我個人覺得應該還是要相加,因為這兩種情況沒有什麼關聯性,還有他們都發生在不同stage,所以感覺是相加比較合理。
可以想像一下一堆branch instructions然後都有被偵測到flow dependences,這時候可能3個threads就不夠了~
QooQ
了解,感謝您的解釋
whz
請問15題的c,為什麼parallel的部分不是除以13(1個Y+12個X)
mt
哈囉,題目有說parallel的部分是用12個X跑的喔~