
人工智慧
人工智慧最早是出現於1950年代,來自於當時電腦科學領域的一群先驅,他們開始探索電腦是否能夠用來思考。人工智慧簡單的定義是:「能自動化的執行一般人類的智慧工作」。
早期的西洋棋程式只有開發者手動建立的規則,所以不能稱作機器學習。許多專家曾經認為,人工智慧能夠透過開發者輸入足夠且大量的規則來達成,這種方法稱為符號式AI (symbolic AI),是AI在1950到1980年代末的主流。
雖然符號式AI可以用來解決像是西洋棋這種規則清楚的問題,但是對於更複雜及更模糊的問題,例如影像辨識、語音辨識及語言翻譯,要找出一個明確的規則是非常困難的,因此機器學習漸漸取代符號式AI的地位。
機器學習
AI先驅Alan Turing在1950年提出了著名的論文「計算機器與智慧」,其中介紹的圖靈測試 (Turing test) 正式描繪AI的關鍵概念,而圖靈機 (Turing Machine) 也成為現今電腦的始祖,大大的改變人類的科技與生活方式。
機器學習源自於這個問題:電腦能否超越聽命行事的侷限,而能自主學習去完成人類交付的任務呢?程式開發者無須手動建立資料的處理規則,而是由電腦檢視資料後自動化學習或思考並找出完成任務的規則。
這個問題打開了一個全新的程式開發大門。在符號式AI開發中,開發者必須手動輸入規則然後機器依這些規則進行處理工作,最後輸出答案。而機器學習是,輸入大量的訓練資料及對應的答案,然後由電腦自行找出規則。這些規則可以被套用到機器未看過的資料並正確的輸出答案。如下圖:
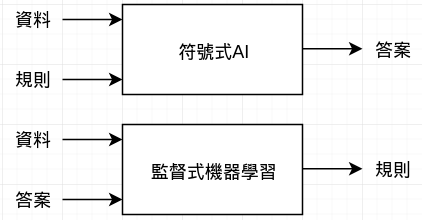
機器學習系統是被訓練,而不是把所有的規則都寫入程式中。經由多次的餵入訓練資料,讓機器能從這些資料中找到統計結構,最後讓系統產生出規則,然後用這些規則來自動化執行任務。
雖然機器學習在1990年代才開始蓬勃發展,但是近年來因為硬體運算能力與更大的資料量,使得機器學習迅速成為AI中最流行的子領域。
資料的轉換表示法
執行機器學習,我們需要3個要素:
- 輸入資料點:舉例來說,如果要進行語音辨識,則資料點可能是人們說話的語音檔案。
- 標準答案:在語音辨識中,標準答案就是由人們產生的逐字搞。
- 評估演算法執行結果好壞的方法:為了衡量演算法目前產出結果與預期結果間的差距,我們必須指定一個測量的方式。並以測量結果作為調整參數的一種回饋信號,而調整的步驟就是我們所謂的學習。
機器學習模型將輸入資料點轉換成有意義的輸出,並且和輸入資料所對應的標準答案進行比對、修正。因此,機器學習和深度學習的核心問題在於要如何有意義的轉換資料,也就是要為這些輸入資料找到適當的表示法,這個表示法會讓我們把輸入資料轉換成更接近預期的輸出結果。所謂的表示法,就是用不同的方式來檢視資料。
尋找表示法的操作方式很多,像是座標調整、線性投影、非線性運作原理等等。這些操作方式會各自構成許多不同可能的表示法,而這些表示法的集合我們稱為假設空間。
機器學習所進行的訓練,就是試著從假設空間裡選擇一個合適的表示法。
深度學習
深度學習是機器學習的一個子領域,採用嶄新的手法從資料中學習到有效的表示法,強調使用連續、多層的學習方式。深度學習中的深度不是指這個方法可以達到更深入的理解,而是呈現出連續多層次表示法的概念。一個深度學習模型使用多少層來處理資料,就是這個模型的深度。現代的深度學習通常會有數十層,甚至數百層以上連續多層的表示法。相對的,其他機器學習方法多半使用1到2層的資料表示法,被稱為淺層學習。
在深度學習中,這種多層次的表示法幾乎都是來自於神經網路 (neural network) 模型。雖然深度學習的一些核心概念來自於我們對大腦運作的理解,但並不是大腦真正運作的模式,沒有任何證據可以證明大腦運作有應用到近代深度學習的學習機制中。你可能常看到一些文章說深度學習的運作模式就如同大腦一般,或仿造大腦來打造的,但事實上不全然是。
深度學習在技術上,是用多階段的方式來學習資料的表示法。雖然只是一個簡單的概念,但事實證明即便是這樣簡單的機制,經過足夠的學習訓練後,將會有如同魔術般的學習結果。
深度學習如何運作
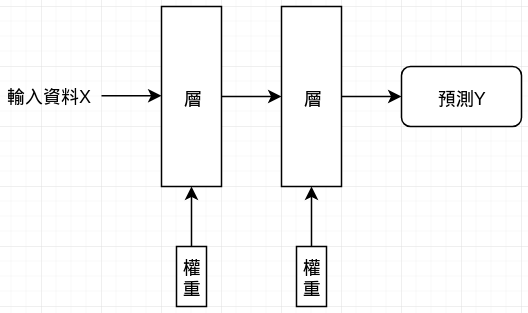
所謂的「層」,會對輸入資料做怎樣的運作,就取決於存在該層的權重 (weight),而權重是由多個數字組成。用技術術語來說,層 (layer) 是藉由權重參數來和資料進行運算以執行資料轉換的工作,因此,權重有時候也被稱為層的參數,而學習的過程其實就是幫神經網路的每一層找出適當的權重參數。在實際運作上,深度神經網路可能包含數千萬個權重,其中一個權重參數被改變,就會影響到其他的權重運作。
為了調整神經網路的權重值,我們必須先評估這個預測值與標準答案相差多少,而這個評估的工作就稱為損失函數 (loss function),也稱為目標函數 (objective function)。
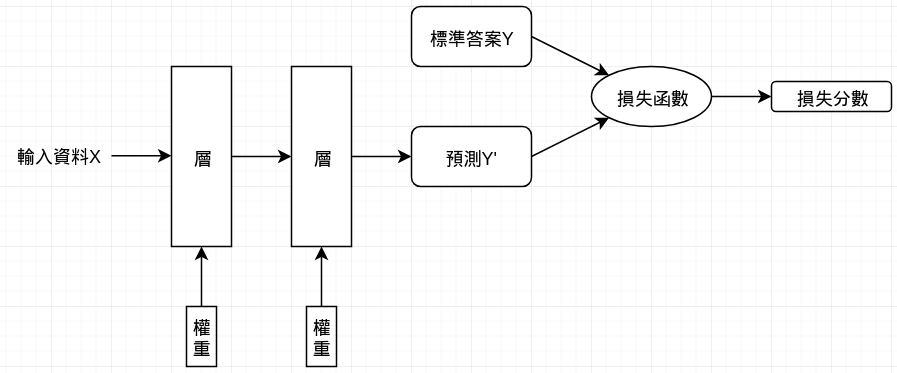
我們利用損失分數當作回饋訊號來調整各層的權重,逐步降低每次學習的損失分數。這樣的工作是由優化器 (optimizer) 來執行的,運用了反向傳播 (Backpropagation) 演算法,也就是深度學習中的核心演算法。
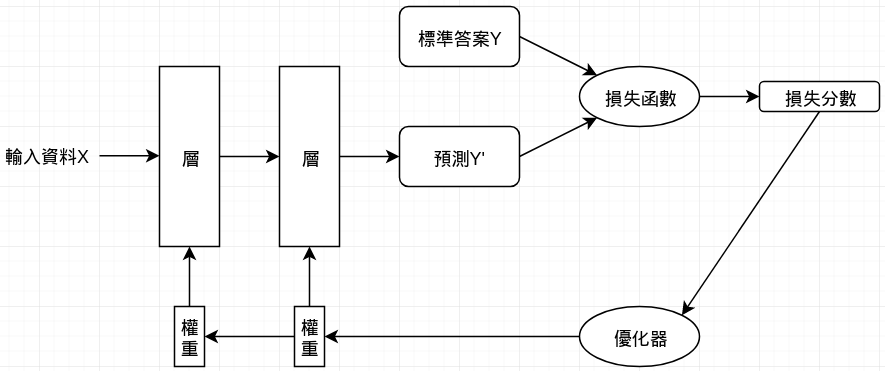
神經網路在最一開始會自動配置一組隨機權重值,然後開始進行轉換。由於是隨機配置,所以一開始的輸出與理想情況相差甚遠,而損失分數也會較高。隨著神經網路多次學習後,損失分數開始下降,這個過程我們稱為訓練循環 (training loop),通常在成千上萬個訓練資料中進行數百次的迭代 (iteration),最後得到一組可使損失函數最小化的權重值。
深度學習的成就
儘管深度學習在機器學習中是一個相對老的子領域,但它在2010年才逐漸嶄露頭角。在一些一直以來被認為是高難度領域中,深度學習已經取得了以下突破:
- 影像分類
- 語音識別
- 手寫轉譯
- 機器翻譯的優化
- 文字轉換語音的優化
- 數位助理
- 自動駕駛
- 網站搜尋引擎的優化
- AlphaGo



發佈留言