

1. (5%) Why is it important to scale up I/O speeds as CPU speed increases?
參考解答:When we’re doing some tasks that needs I/O operations, I/O speeds is very important, if we don’t increase the speed of I/O devices, they will become the bottleneck of the entire system and slow down the performance.
2. (5%) Including the initial parent process, how many processes are created by the following program? Justify your answer by drawing a tree of processes.
#include <stdio.h>
#include <unistd.h>
int main()
{
fork();
fork();
fork();
return 0;
}參考解答:8,
3. (15%) Answer the following questions regarding processes and threads.
(a) Is the following statement true or false? When a user-level thread makes a blocking system call, only the thread that makes the system call is blocked. (Use no more than 20 words to justify your answer.)
(b) Is the following statement true or false? An I/O-bounded process will be more likely to be favored by the CPU-scheduler over a CPU-bounded process. (Use no more than 20 words to justify your answer.)
(c) Choose the correct answer. Consider the following preemptive priority scheduling algorithm based on dynamically changing priorities. Larger priority numbers imply higher priority. When a process is waiting for the CPU (in the ready queue, but not running), its priority changes at a rate $\alpha;$ when it is running, its priority changes at a rate $\beta.$ All processes are given a priority 0 when they enter the ready queue. What is the algorithm that results from $\beta > \alpha > 0$?
A. Non-preemptive SJF
B. Preemptive SJF
C. FCFS
D. Non-preemptive priority
E. Multilevel feedback queue
F. None of the above(d) Choose the correct answer. The Banker’s algorithm ensures that a system will never enter an unsafe state. In order to implement it, the algorithm:
G. Checks that the maximum request of every process does not exceed the amount of the systems' available resources.
H. Checks that in every order that we schedule the processes, there will never be a deadlock.
I. Checks that there is at least one order in which we can schedule the processes, in which there is no deadlock.
J. Checks that the maximum request of at least one process does not exceed the amount of the systems' available resources.
K. None of the above.(e) Consider a system with $r$ identical resources. The system has 15 processes each needing a maximum of 15 resources. What is the smallest value for $r,$ which makes the system deadlock-free, without a need to use a deadlock avoidance algorithm? Justify your answer.
參考解答:(a) F (b) T (c) D (d) I (e) 211
4. (5%) Consider the following two processes, A and B, to be run concurrently in a shared memory (all variables are shared between the two processes).
PROCESS A:
for i := 1 to 5 do
x := x + 1
od
--------------------
PROCESS B:
for i := 1 to 5 do
x := x + 1
odAssume that load (read) and store (write) of the single shared register $x$ are atomic, $x$ is initialized to 0, and $x$ must be loaded into a register before being incremented. What will be the possible value for $x$ after both processes have terminated? Justify your answer.
參考解答:$x = 5,6,7,8,9,10$
5. (10%) Page faults can decrease CPU utilization since when a page fault occurs, the process requesting the page must block while waiting for the page to be brought from disk into physical memory. Here we model the CPU utilization as
$$\text{CPU utilization }\dfrac{\text{T}_{\text{exec}}}{\text{T}_{\text{exec}} + \text{T}_{\text{idle}}}$$
where $\text{T}_{\text{exec}}$ is the time for instruction execution and $\text{T}_{\text{idle}}$ is the time that CPU is idle because of page fault. Suppose each page fault takes 8 millisecond to resolve, and each instruction takes 1 nanosecond to execute.
(a) Suppose there is only one process executed by CPU. and its reference string is 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1. The least-recently-used (LRU) algorithm is used for page replacement. When 3 physical frames are assigned to the process, the CPU utilization is 0.5. What is the CPU utilization if 4 physical frames are assigned to the process?
(b) OS usually increases the CPU utilization by increasing the degree of multiprogramming. If the page fault frequency (PFF) is 1 page fault per $10^7$ instructions, what is the minimum number of processes need be scheduled to reach full CPU utilization? The time of context switch is negligible and assumed no thrashing occurs.
參考解答:(a) 60% (b) 2
6. (5%) Give the reasons why the operating system might require accurate information on how blocks are stored on a disk. How could the operating system improve file system performance with this knowledge? Briefly justify your answers.
參考解答:We need to know how and where the files are stored on the disk in order to apply the best disk scheduling algorithm. To improve the performance, we can save blocks in the same cylinder so the heads doesn’t need to move often.
7. (5%) There are three common space allocation methods in the file system design (1) contiguous allocation, (2) linked allocation, (3) indexed allocation. For a database system with limited memory, which method would you recommend to use? Briefly justify your answers.
參考解答:Contiguous allocation doesn’t need link pointers memory and it supports random access. So is the best choice in this case.
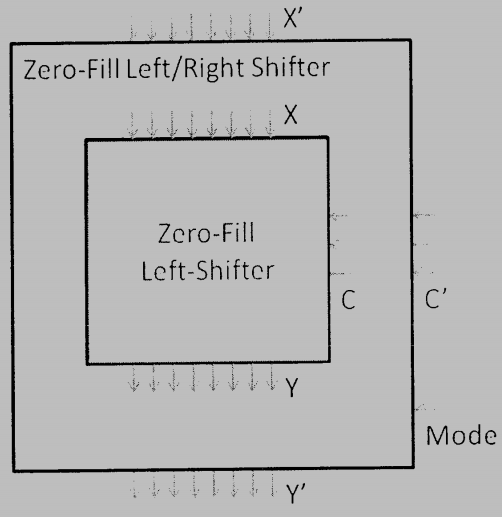
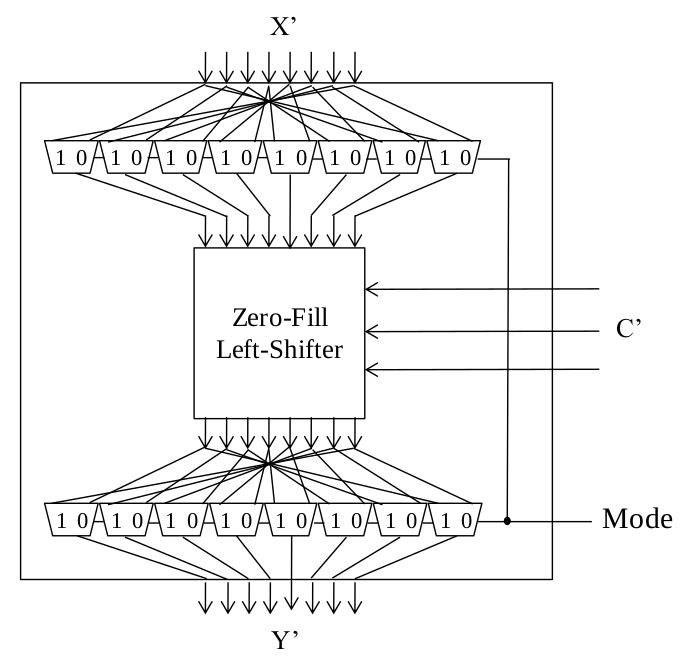
8. (10%) Given an 8-bit zero-fill left-shifter as shown below that has 8 input bits $X = X_7X_6…X_0,$ 8 output bits $Y = Y_7Y_6…Y_0,$ and 3-bit shift-amount-control $C = C_2C_1C_0.$ For example, when $X = 10110011$ and $C = 011,$ the input will be left-shifted by 3 bits and three vacant bits are filled with zeros to get $Y = 10011000.$ Add some circuit to the shifter so that it become a zero-fill left/right shifter capable of both left-shift and right-shift operations with $X’,Y’$ and $C’$ as its input, output, and shift-amount, respectively. An additional bit called “Mode” selects the shift direction: “0” for left shift and “1” for right shift.
參考解答:
9. (10%) A benchmark is used to design a microprocessor called LHOR with five instruction classes and their dynamic statistics is as follows:
| Class | Statistics |
| ALU instructions | 50% |
| Loads | 20% |
| Stores | 14% |
| Branches | 12% |
| Jumps | 4% |
Two implementations are compared, i.e., the single-cycle implementation and multi-cycle implementation. The critical path, which is 60ns, exists in the Load-type instruction class for the single-cycle implementation. The multi-cycle design is done by partitioning the Load-type instruction to 6 stages, reducing the cycle period. Assume that the pipeline register introduces additional 2ns delay to each stage. Adopting the multi-cycle implementation, the number of clock cycles for each instruction class is listed as follows:
| Class | Cycle |
| Loads | 6 |
| Stores | 5 |
| ALU instructions | 4 |
| Branches | 4 |
| Jumps | 3 |
(a) What is the ratio between numbers of execution cycles for the multi-cycle implementation and the single-cycle one based on this benchmark?
(b) What is the performance speedup of the multi-cycle design?
參考解答:(a) 4.5 (b) 1.11
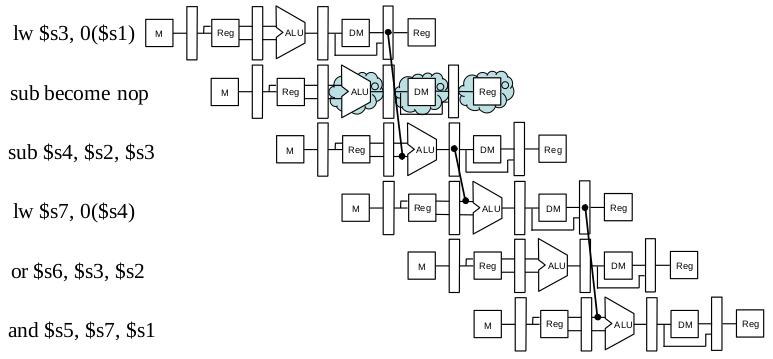
10. (10%) Consider the five-stage pipelined datapath of MIPS processor that consists of IF (instruction fetch), ID (instruction decode and register file read), EX (execution or address calculation), MEM (data memory access) and WB (write back).
(a) Identify all dependences and hazards of the following code segment.
lw $s3, 0($s1) # load word from address of $s1 to $s3
sub $s4, $s2, $s3 # reg $s4 = reg $s2 - reg $s3
lw $s7, 0($s4) # load word from address of $s4 to $s7
or $s6, $s3, $s2 # reg $s6 = reg $s3 | reg $s2
and $s5, $s7, $s1 # reg $s5 = reg $s7 &amp;amp;amp;amp; reg $s1(b) Complete the pipeline schedule of the code segment of (a) using the pipeline diagram. Show all occurrence of data forwarding and pipeline stall, if necessary, to solve the hazards in an optimized way. Hint: start with the following graphical representation to show the result.

參考解答:
(a)

(b)
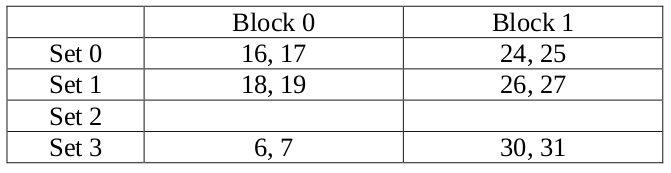
11. (10%) Consider the sequence of memory reads below (decimal word address): 17, 10, 6, 1, 30, 22, 27, 16, 19, 31, 7, 24.
Assume that the cache is 2-way set associative, block size = 16 bytes, word size = 64 bits, the capacity of data part = 128 bytes. Also assume it employs the Least-Recently Used (LRU) replacement strategy and is initially empty.
(a) Label each read in the sequence as a Hit or a Miss.

(b) Show the final content of each block in the cache.
參考解答:
(a)
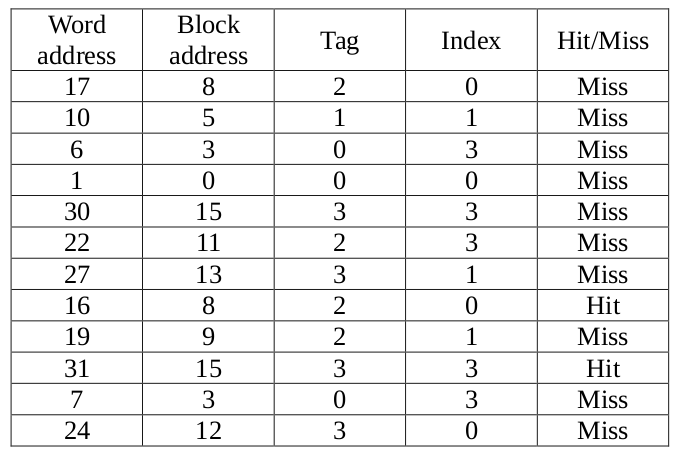
(b)
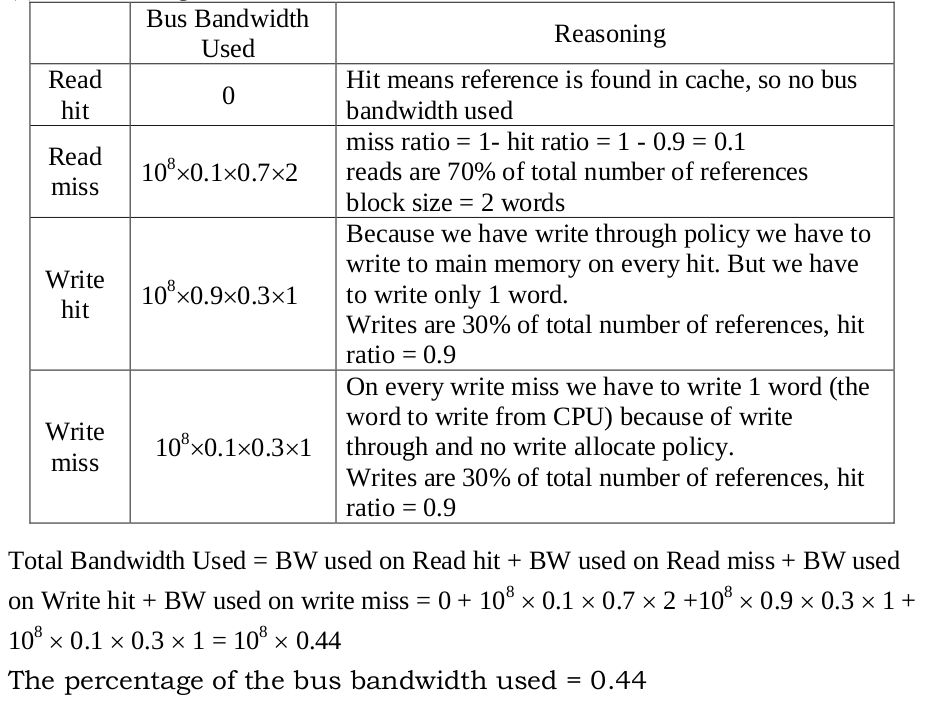
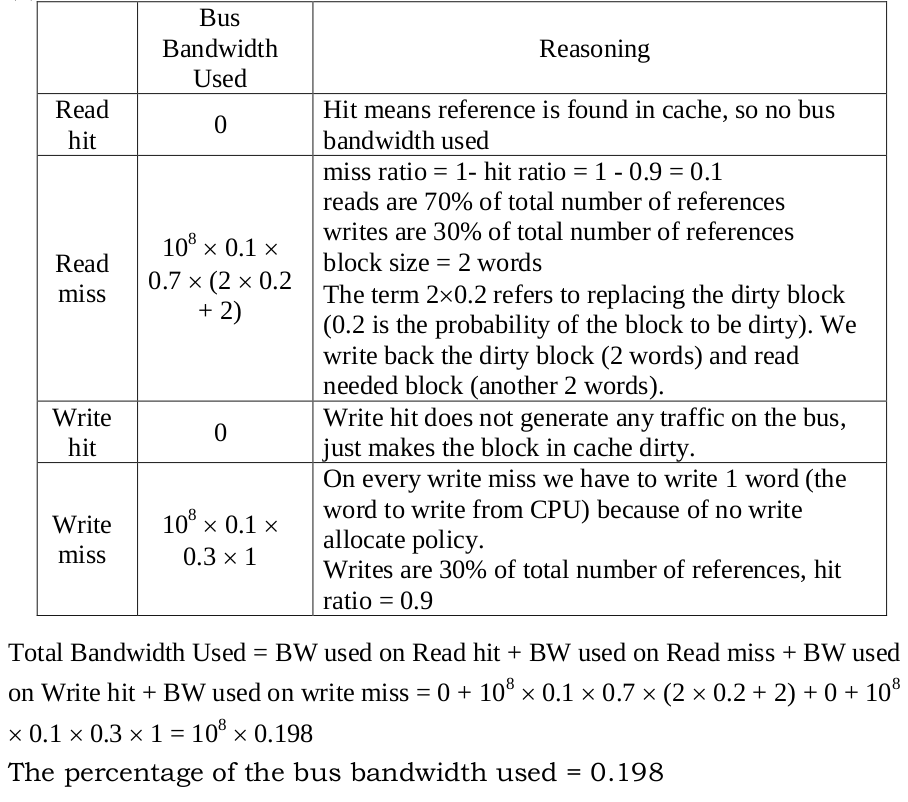
12. (10%) Assume a memory system has the following characteristics:
(1) The CPU sends references to cache at the rate of $10^8$ words per second.
(2) 70% of those references are reads.
(3) The memory system supports $10^8$ words per second, reads or writes.
(4) The bus reads or writes a single word at a time.
(5) The hit rate for the memory accesses is 90%.
(6) A two-word cache block is read in upon any read miss.
(7) 20% of blocks in the cache have been modified at any given time.
(8) The cache uses no-write allocate on a write miss.
Calculate the percentage of memory bandwidth used on the average in the following two cases:
(a) The cache is write through.
(b) The cache is write back.
參考解答:
(a)
(b)
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



QooQ
想請問第三題的(c)為什麼不是D呢?,我的想法是這樣
在ready queue的process priority 變化量小於running process的priority變化量
因為初始priority都為0,也就是說running process的priority 永遠大於ready queue內的process
因此除非running process自願否則不會被preempt,感謝~
mt
你的想法非常合理,當初肯定是剛起床的時候寫這題的哈哈,謝謝你。
QooQ
好的,非常感謝您
Jackson
請問,第 4 題,答案是否是介於 1 ~ 10 ?
因為有可能在 read 的時候都是 read 到 initalized data 而只加到一次
mt
基本上不可能會有1到4的output喔!因為他是兩個processes執行for loop所以可以把程式碼看成是這樣:
—————
Process A:
load x
inc x
store x
load x
inc x
store x
load x
inc x
store x
load x
inc x
store x
load x
inc x
store x
—————
Process B:
load x
inc x
store x
load x
inc x
store x
load x
inc x
store x
load x
inc x
store x
load x
inc x
store x
—————
最極端的情況就是Process A load完一開始的x就給Process B跑,然後Process B跑完才讓Process A繼續執行這樣就是5。
可以思考一下,有不懂歡迎再跟我討論喔~
Jackson
了解 謝謝
Ben
想請問第9題(b)選項的1.13是怎麼來的呢?
我有一些想法,不知道是否正確:
1. 題目提到用single cycle實作時load指令的critical path 60 ns,再加上load被分成6 stages,也就是會使用6個functional units,因此我假設每個units的delay是10 ns。
2. 在計算pipeline register delay 時,看該指令會需要經過多少pipeline register,而各類指令會經過的pipeline register數量是:R-type/load : 5, save : 4, branch : 3, jump : 2
所以我的答案是 60/(0.2*(60+10) + 0.14*(50+8) + 0.5*(40+10) + 0.12*(40+6) + 0.04*(30+4)) = 60/54 = 1.11
mt
我剛重算了一下答案確實是60 / 54 = 1.11,不過我的算法是60 / (0.2 * (6 * 12) + 0.14 * (5 * 12) + 0.5 * (4 * 12) + 0.12 * (4 * 12) + 0.04 * (3 * 12)) = 60 / 54 = 1.11。題目是說因為pipeline register所以會讓每個stage帶來額外的delay,所以可以直接設clock cycle是10 + 2 = 12ns。