

1. (10%) Suppose that a disk drive has 1000 cylinders, numbered 0 to 999. The drive is currently serving a request at cylinder 200. The queue of pending requests, in FIFO order, is 80, 910, 190, 120, 10, 280, 900
Starting from the current head position, what is the reading order from each of the following disk-scheduling algorithm? (no need to compute the total distance)
(a) SSTF
(b) SCAN (move to higher number first)
(c) C-SCAN (move to higher number first)
Note that SSTF stands for shortest-seek-time-first and C-SCAN stands for circular SCAN.
參考解答:
(a) 200→190→120→80→10→280→900→910
(b) 200→280→900→910→190→120→80→10
(c) 200→280→900→910→10→80→120→190
2. (4%) Figures (a) and (b) below depict two different RAID designs where Xp is the parity bit of data X. Explain what is the main advantage of the RAID in Fig.(b) over the RAID in Fig.(a).
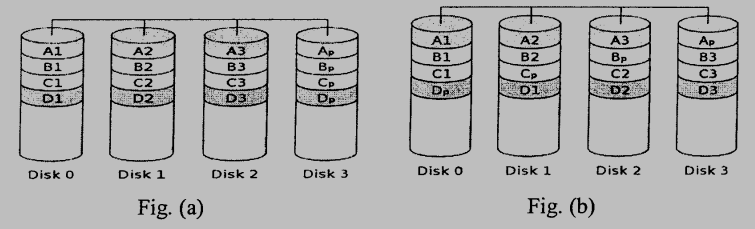
參考解答:Fig.(a) is either RAID 3 or RAID 4 which the parity disk is the bottleneck and we can’t do multiple small writes at the same time. Fig.(b) is RAID 5 which splits the parity disk into several parts, allowing us to perform multiple small writes at the same time.
3. (10%) Suppose we have a demand paged memory. In the system, we try to reduce the page faults with LRU and FIFO replacement schemes, respectively. Consider the following two C programs: Program A and Program B. Assume that the number N in the program is sufficiently large.
Program A
#include <stdio.h>
double A[N][N];
double Anew[N][N];
Compute() {
int i, j;
for (i = 1; i < (N-1); i++)
for (j = 1; j < (N-1); j++)
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i+2] + A[j][i-1]);
}Program B
#include <stdio.h>
double A[N][N];
double Anew[N][N];
Compute() {
int i, j;
for (j = 1; i < (N-1); j++)
for (i = 1; j < (N-1); i++)
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i+2] + A[j][i-1]);
}(a) Assume LRU replacement algorithm is used. Which program will be likely with less page faults? Please explain the reason.
(b) Assume FIFO replacement scheme is used. Which program will be likely with less page faults? Please explain the reason.
參考解答:Assume the system store arrays in row-major format and page size = N-2 elements and with limited (less than N-2) frames.
(a) Program B will occur less page faults than Program A, because Program B is accessing the array in row-major format, so there will be only N-2 page faults in total.
(b) 同上
Note: 都是 Compulsory miss 用 LRU, FIFO沒有差別。
4. (4%) Which of the following programming techniques and structures are good for a demand-paged environment? Which are “not good”? Explain your answers.
(a) Stack
(b) Sequential Search
(c) Vector operations
(d) Indirection
參考解答:Good: a, b, c Bad: d
5. (9%) Consider a system running two I/O-bound processes, P1 and P2, and one CPU-bound process, P3. Assume that each I/O-bound process issues an I/O operation after 0.9 millisecond of CPU computing and that each I/O operation takes 8.9 milliseconds to complete. Assume multiple I/O operations can be executed simultaneously without causing any delay. Also assume that the context switching takes 0.1 millisecond and that all processes are long running tasks. Suppose the Round-Robin scheduler is used and the time quantum is 3.9 millisecond.
(a) Suppose initially the processes in the waiting queue are P1, P2, and P3. Draw the Gantt chart for the first 20 milliseconds.
(b) What is the CPU utilization in the long run?
(c) What is the throughput of I/O operations (per second) in the long run?
參考解答:
(a)

(b) 13.513.8≈0.98
(c) 145 I/O operations per second
6. (8%) Synchronization barrier is a common paradigm in many parallel applications. A barrier is supposed to block the calling thread until all N threads have reached the barrier. The following code uses semaphores to implement the barrier function. The initial values of variables are
N = 2 (which means there are two processes, P1 and P2.)
count = 0
R1 = Semaphore(1)
R2 = Semaphore(0)
R1.wait()
count = count + 1
if (count == N) R2.signal()
R2.wait()
R2.signal()
R1.signal()(a) Show that the execution sequence P1(1), P1(2), P1(3), P1(4), P2(1) causes a deadlock, where Pi(j) means process i executes line j.
(b) Draw the Resource-Allocation Graph for the system after the execution sequence.
(c) Does your Resource-Allocation Graph have a cycle? If yes, label each edge with an execution code Pi(j) that creates the edge. If no, explain why your Resource-Allocation Graph cannot detect the deadlock.
(d) Rearrange the above code to produce a correct implementation of synchronization barrier without any deadlock for arbitrary execution order of P1 and P2. Give your answer in a permutaion of number 1 to 6.
參考解答:
(a) P1 will stuck at line 4 waiting someone to signal R2, but R1 won’t be signaled, so deadlock occurs. P2 stuck at line 1.
(b)
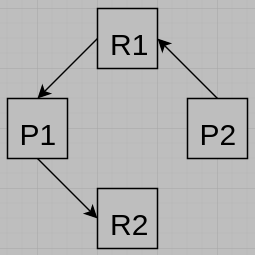
(c) No, to use the RAG to detect deadlock, we need to make sure all resources have only one instance. In this case, resource R2 have no instances, that’s why we can’t detect deadlock with this RAG.
(d) 1, 2, 6, 3, 4, 5.
7. (8%) Give the table of latencies of individual stages of a MIPS instruction, please answer the following questions:
| Instruction fetch | Register read | ALU operation | Data access | Register write |
| 200ps | 100ps | 250ps | 400ps | 100ps |
(a) What is the clock cycle time in a nonpipelined and pipelined processor?
(b) What is the total latency of a lw instruction in a nonpipelined and pipelined processor?
(c) If the time for an ALU operation can be shortened/increased by 25%, how much speedup/slowdown will it be from pipelining? Explain the reason.
(d) If you can split one stage into two, each with half the original latency, to improve the pipelining performance. Which stage would you split and what is the new clock cycle time in a pipelined processor?
參考解答:
(a) Nonpipelined: 1050ps, Pipelined: 400ps.
(b) Nonpipelined: 1050ps, Pipelined: 2000ps.
(c) Shortening/Increasing the ALU operation will not affect the speedup/slowdown obtained from pipelining. It would not affect the clock cycle.
(d) Data Access stage. New clock cycle time: 250ps.
8. (8%) Please answer the following questions about interfacing I/O devices to the processor and memory:
(a) Describe the following terminologies:
- Memory-mapped I/O.
- I/O instruction.
- Device pooling.
- Interrupt-driven communication.
(b) Which communication pattern is most appropriate for a “Video Game Controller”? Explain.
(c) Prioritize the following interrupts caused by different devices:
- Mouse Controller.
- Reboot.
- Overheat.
參考解答:
(a)
Memory-mapped I/O: An I/O scheme in which portions of address space are assigned to I/O devices and reads and writes to those addresses are interpreted as commands to the I/O device.
I/O instruction: A dedicated instruction that is used to give a command to an I/O device and that specifies both the device number and the command word (or the location of the command word in memory).
Device polling: The process of periodically checking the status of an I/O device to determine the needs to service the device.
Interrupt-driven communication: An I/O scheme that employs interrupts to indicate to the processor that an I/O device needs attention.
(b) Device polling
(c) Overheat: 1, Reboot: 2, Mouse Controller: 3.
9. (5%) In general, a fully associative cache is better than a direct-mapped cache in term of miss rate. However, it is not always the case for a cache, especially for a small cache. Please design an example to demonstrate that a direct-mapped cache outperforms a fully associative cache in term of miss rate under the replacement policy, Least Recently Used (LRU).
參考解答:
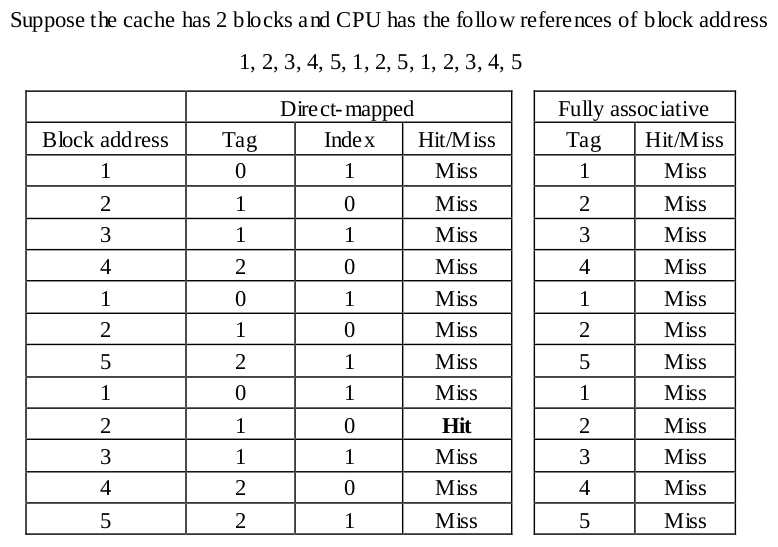
This example shows the miss rate for fully associative cache is higher than that of the direct-mapped cache.
10. (10%) Consider adding a new index addressing mode to the machine A such that the following code sequence
ADD R1, R1, R2 // R1 = R1 + R2
LW Rd, 0(R1) // Loadcan be combined as
LW Rd, 0(R1 + R2)(a) Assume that the load and store instructions are 10% and 20% of all the benchmarks considered, respectively, and this new addressing mode can be used for 5% of both of them. Determine the ratio of instruction count on the machine A before adding the new addressing mode and after adding the new addressing mode.
(b) Assume that adding this new addressing mode also increases the clock cycle by 3%, which machine (either machine A before adding the new addressing mode or machine A after adding the new addressing mode) will be faster and by how much?
參考解答:
(a) 10098.5≈1.015
(b) 1.01455
11. (8%) The following Boolean equation describe a 3-output logic function.
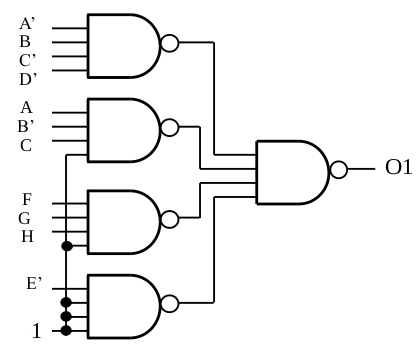
O1 = A'BC'D' + AB'C + FGH + E'
O2 = BCD + CDE'H + FGH'
O3 = AB'CD + ABEF + F'G'(a) Draw a circuit diagram for O1 using only 4-input NAND gates.
(b) If the 3-output function is implemented with a read-only memory, what size of ROM is needed?
參考解答:
(a)
(b) 28×3 bits=768 bits
12. (8%) Assume the floating point is stored in a 32 bits wide format. The leftmost bit is the sign bit, the exponent of 16 in excess-64 format is 7 bit wide, and the mantissa is 24 bits long and a hidden 1 is assumed.
(a) What is the smallest positive number representable in this format (write the answer in hex and decimal)?
(b) What is the largest positive number representable (write the answer in hex and decimal)?
(c) Assume A=2.34375×10−2 and B=2.9015625×102. Write down the bit pattern using this format for A and B.
(d) Using the format presented in (c), calculate the A – B.
參考解答:
注意:(c)的format for A的exponent為0111111。

13. (8%) Assume garage collection comprises 30% of the cycles of a program. There are two methods used to speed up the program. The first one would be automatically handle garbage collection in hardware. This causes an increase in cycle time by a factor of 1.4. The second one provides new hardware instructions that could be used during garbage collection. This would use only one-third of instructions needed for garbage collections but increase the cycle time by 1.2. Compute the program execution time for both methods and show which one is better.
參考解答:The second option is the best choice.
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



QQ
想問5.(c)的詳解, 感恩!
mt
13.8ms是一個循環,又因為P1跟P2總共兩次I/O,可以算出一秒有2 * (1000 / 13.8) = 144.927。
QQ
感恩! 順便想請問一下12.(a)那個應該是16的-62次方吧, 是我觀念錯了嗎, 因為你的binary format 寫出來確實是-62次方
mt
題目有說excess-64 format,所以要-64喔~不是用一般的bias。
AA
想請問13.詳解
mt
第一種方法的話執行時間會變原本的(1 – 0.3) * 1.4 = 0.98倍,第二種方法則是(1 – 2/3 * 0.3) * 1.2 = 0.96倍,所以第二種會更快一些。
leo
你好,想請教 12.c 的 A,我的理解是其無號數表示值為 63,故是用 0 0111111 011000000000000000000000 表示,但解答的指數部分是寫 1111111。感謝!
mt
答案寫錯了~你是對的,謝謝你。
Ben
想請問 10. (a) (b) 詳解。
題目的說法是指每個 lw/sw 都會固定與一個 add 一起執行嗎? 如果不是,那我該怎麼得到新的指令數呢?
mt
對!題目的意思就是說新的LW/SW會等於舊版的ADD + LW/SW,所以(a)就為了方便計算假設有100個指令,則答案為100 / (100 – 10 * 0.05 – 20 * 0.05) = 100 / 98.5 = 1.015。
(b)則是原本的機器比較快,快了(98.5 * 1.03) / 100 = 1.01455倍。