

1. [10%] Explain the following term in English. For each term, please use less than 100 words.
(a) Power Wall
(b) GPGPU
(c) Restartable instruction
(d) Write-allocate policy
(e) NUMA
參考解答:
(a) Power wall: the trend of consuming exponentially increasing power with each factorial increase of operating frequency. The power wall is forcing a design toward simpler and more power-efficient processors on a chip.
(b) GPGPU: Using a GPU for general-purpose computation via a traditional graphics API and graphics pipeline.
(c) Restartable instruction: An instruction that can resume execution after an exception is resolved without the exception’s affecting the result of the instruction.
(d) Write-allocate policy: When a write miss occurs, the corresponding block is fetched from memory and then the appropriate portion of the block is overwritten.
(e) NUMA: A type of single address space multiprocessor in which some memory accesses are much faster than others depending on which processor asks for which word.
2. [10%] Suppose we have developed new versions of a processor with the following characteristics.
| Version | Voltage | Clock rate |
| Version 1 | 1.2 V | 810 MHz |
| Version 2 | 1 V | 1 GHz |
(a) How much has the dynamic power been reduced if the capacity load does not change?
(b) Assuming that the capacity load of version 2 is 80% the capacity load of version 1, find the voltage for version 2 if the dynamic power of version 2 is reduced by 20% from version 1.
參考解答:
(a) $\dfrac{1000 \times 1^2}{810 \times 1.2^2} = 0.857 \approx 0.86 \to \text{dynamic power been reduced by } 14\%$
(b) $\dfrac{1000 \times 0.8C \times V^2}{810 \times C \times 1.2^2} = 0.8 \to V = 1.08 Voltage$
3. [5%] Translate the following C code to MIPS instructions. Assume that the variables $c$ and $d$ are assigned to registers \$s0 and \$s1, respectively. Assume that the base address of the arrays $A$ and $B$ are in registers \$s6 and \$s7, respectively.
c = d - A[B[2]];參考解答:
lw $t0, 8($s7)
sll $t0, t0, 2
add $t0, $s6, $t0
lw $t1, 0($t0)
sub $s0, $s1, $t14. [5%] What decimal number goes the following bit pattern represent if it is a floating point number? Use the IEEE 754 standard.
$$101011111011010000000000$$
參考解答:
$(-1)^1 \times (1.01101) \times 2^{95-127} = -1.01101_2 \times 2^{-32} = -1.40625_{10} \times 2^{-32}$
Note: There are something wrong in this problem because only 24 bits in the given bit pattern.
5. [20%] Assume an instruction pipeline for a high-speed, load/store processor with the following instruction classes
ALU ALUop Rdst, Rsrc1, Rsrc2
ALUimmediate ALUiop Rdst, Rsrc1, imm
Load MEMop Rdst, n(Rsrc)
Store Memop n(Rsrc2), Rsrc1
Conditional branch BRop Rsrc1, Rsrc2, offset
Jumps JMP RdstEach instruction takes one machine word. The only memory-addressing mode supported is base register plus a signed offset. Conditional branches compare the two branch source operand values using the ALU. The branch target address is computed on a separate address generation adder contained in the control unit of the machine. Register file writes occur in the first half of a cycle and register file reads occur in the second half.
The machine uses virtual memory address, with separate instruction and data TLBs. It also has a physical addressed (tagged) direct mapped L1 Icache and a physically addressed set associate L1 Dcache (Accesses that miss in the L1 cache cause the instruction pipeline to stall.) The ALU used during the EX cycle is pipelined and takes one cycle to complete an addition/subtraction/logical operations and two cycles to complete a multiplication. The time taken by the key components (that already includes the pipeline register write time, the interconnect delay, and any necessary multiplexors) is as follows:
I o D TLB access 1 ns
Icache access 2 ns
Instruction decode 1 ns
Address adder 1 ns
Dcache access 2 ns
ALU pipe stage 2 ns
RegFile read/write 2 ns per 2 port accessAnswer the following questions about your pipeline.
(a) Draw the shortest possible instruction pipeline (i.e. the pipeline with the fewest stages) while ensuring that there are no structural hazards. For your pipeline, give a name for each stage along with a short description of what activities occur during that stage.
(b) What is its clock rate?
(c) Give a MIPS instruction example of two different data hazards that can be solved by forwarding (both data hazards should be different in that the forwarding is handled from different pipeline stages). For each, indicate how many stalls are incurred before the hazard is resolved.
(d) Give MIPS instruction example of two different data hazards that cannot be solved by forwarding. For each, indicate how many stalls are incurred before the hazard is resolved.
參考解答:
(a)
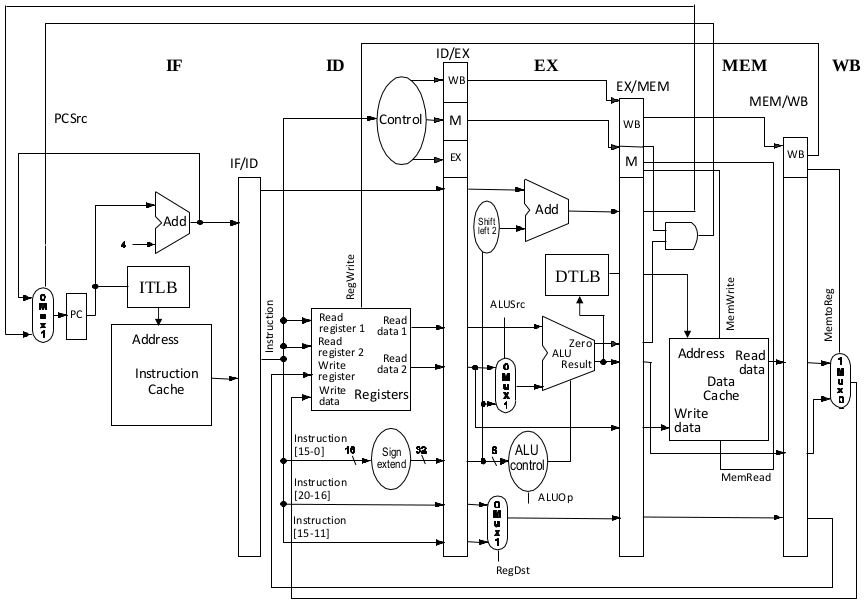
(b) The longest stage time = 1 ns + 2 ns = 3 ns (ITLB + Dcache or ALU + DTLB) $\to$ clock rate = 0.33 GHz
(c)
Example 1:
add $s1, $s2, $s3
sub $s4, $s1, $s2
Example 2:
add $s1, $s2, $s3
slt $s5, $s6, $s7
sub $s4, $s2, $s1(d)
lw $s1, 12($s2)
add $s2, $s1, $s36. [10%] Consider the following page reference string:
$$1, \, 2, \, 3, \, 4, \, 2, \, 1, \, 5, \, 6, \, 2, \, 1, \, 2, \, 3, \, 7, \, 6, \, 3, \, 2, \, 1, \, 2, \, 3, \, 6.$$
(a) In the LRU page-replacement algorithm, how many page faults would occur when we have ‘one’, ‘two’, ‘three’ page frames? Please indicate the number of page faults individually. Assume that all frames are initially empty, and therefore your first access to each unique page will cause one fault.
(b) In the optimal page-replacement algorithm, how many page faults would occur when we have ‘one’, ‘two’, ‘three’ page frames? Please indicate the number of page faults individually. Assume that all frames are initially empty, and therefore your first access to each unique page will cause one fault.
參考解答:
(a) 1 frame: 20, 2 frames: 18, 3 frames: 15.
(b) 1 frame: 20, 2 frames: 15, 3 frames: 11.
7. [10%] Choose the correct answers for each of the following 5 questions.
(a) The Banker’s Algorithm is proposed to support the technique of:
(1) deadlock detection
(2) deadlock recovery
(3) deadlock avoidance
(4) deadlock identification
(b) For two processes accessing a shared variable, Peterson’s algorithm must satisfy:
(1) semaphores
(2) mutual exclusion
(3) synchronization
(4) progress
(5) bounded-waiting
(c) Indefinite blocking may occur if we add and remove processes from the list associated with a semaphore in _____ order.
(1) first in, first out
(2) first in, last out
(3) last in, first out
(4) last in, last out
(d) A CPU-bound process _____.
(1) infrequently requests I/O operations and spends more of its time performing computational work
(2) frequently requests I/O operations and spends more of its time performing computational work
(3) infrequently requests I/O operations and spends less of its time performing computational work
(4) frequently requests I/O operations and spends less of its time performing computational work
(e) _____ increases CPU utilization by organizing jobs (code and data) so that the CPU always has one to execute.
(1) Multithreading
(2) CPU scheduling
(3) Swapping
(4) Multiprogramming
參考解答:(a) 3 (b) 2,4,5 (c) 2,3 (d) 1 (e) 4
8. [15%] To create a new process from processes, the multitasking operating systems such as Unix-like systems provide a “fork” system call. The fork function will create a copy of itself to a child process, and then other programs are executed in the child process.
(a) In the following example with the fork function, how many lines of “NCKU” will be shown in the console?
int main(int agrc, char **argv)
{
int i;
for (i = 0; i < 5; i++)
{
fork();
}
printf("NCKU\n");
return 0;
}(b) In the following example with the fork function, how many lines of “NCKU” will be shown in the console?
int main(int agrc, char **argv)
{
int i;
for (i = 0; i < 10; i++)
{
printf("NCKU\n");
fork();
}
return 0;
}(c) In the following example with the fork function, what content will be printed in the console?
int main(int agrc, char **argv)
{
int x = 0, i = 0;
for (i = 0; i < 3; i++)
{
fork();
x = x + 5;
}
printf("x = %d\n", x);
return 0;
}參考解答:(a) 32 (b) 1023 (c) 8個15
9. [15%] The following implementation in Java is created for a specific system utility.
(a) Could you figure out what is the system utility that can be provided from ‘Manager’ class? Please also simply discuss its corresponding methodology.
(b) Consider ‘Manager’ is used in the multi-threading mode. Is the implementation logically risky? If it is risky, please clearly point out those incorrect methods or lines, and also revise the code (written in Java). If it is not risky, please clarify your answer.
$$程式碼請看原檔$$
參考解答:略
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



發佈留言