

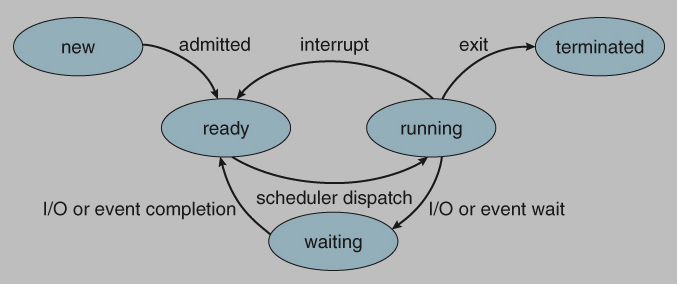
1. (5%) A process can be in one of the following states: new, ready, waiting, running and terminated and the state transition events include admitted, interrupt, I/O completion, I/O wait, dispatch and exit. Please draw a diagram showing the life cycle of a process using above states and events.
參考解答:
2. (10%) Consider the following set of processes, with the length of the CPU-burst time given in milliseconds: The processes are assumed to have arrived in the order P1, P2, P3, P4, P5, all at time 0. Please answer the following questions, given 2 scheduling algorithms, Shortest-Job-First (SJF) and Non-Preemptive Priority (a smaller priority number implies a higher priority):
| Process | Burst Time | Priority |
| P1 | 10 | 3 |
| P2 | 2 | 1 |
| P3 | 4 | 3 |
| P4 | 2 | 4 |
| P5 | 6 | 2 |
(a) Draw Gantt charts illustrating the execution of these processes using the two scheduling algorithms.
(b) What is the turnaround time of each process for each of the two scheduling algorithms?
參考解答:
(a)


(b)
| P1 | P2 | P3 | P4 | P5 | |
| SJF: | 24 | 2 | 8 | 4 | 14 |
| NPP: | 18 | 2 | 22 | 24 | 8 |
3. (5%) Show that, if the wait() and signal() semaphore operations are not executed atomatically, then mutual exclusion may be violated.
參考解答:If wait() and signal() are not executed atomically, the values of the semaphore counter can be access and change by two different process at the same time, causing them to enter the critical section together, then mutual exclusion is violated.
4. (5%) Two processes, A and B, each need three records, 1, 2, and 3, in a database. If A asks for them in the order 1, 2, 3, and B asks for them in the same order, deadlock is not possible. However, if B asks for them in the order 3, 2, 1, then the deadlock is possible. With three resources, there are $3! (=6)$ possible combinations each process can request the resources. What fraction of all combinations is guaranteed to be deadlock free?
參考解答:$\dfrac{1}{3}$
5. (6%) What is the purpose of paging the page table?
參考解答:Reduce size of the page table
6. (4%) Consider a demand-paging system with the following time-measured utilizations: CPU utilization 25%, Paging disk 97%, Other I/O devices 10%. Which (if any) of the following will (probably) improve CPU utilization? Explain your answer.
(a) Install a faster CPU.
(b) Increase the degree of multiprogramming.
參考解答:
(a) No. Thrashing is occuring, installing a faster CPU won’t change or improve the utilization.
(b) No. Thrashing is occuring, if we increase the degree of multiprogramming, thrashing issue will become worst, and even decrease the CPU utilization.
7. (10%) In an i-node based file system implementation, the i-node typically stores 12 direct block pointers, one 1-indirect (single-indirect) block pointer, one 2-indirect (double-indirect) block pointer, and one 3-indirect (triple-indirect) block pointer. Recall that an indirect block is a disk block storing an array of disk block addresses (i.e. pointers). The pointers in a 1-indirect block point to disk blocks that store file data. The pointers in a 2-indirect (or 3-indirect) block point to other 1-indirect (or 2-indirect) blocks. Suppose the file system is configured to use a block size of $2^{10}$ bytes and each pointer takes up 4-byte.
(a) What is the maximum number of pointers stored in a 1-indirect block?
(b) What is the maximum file size (in Bytes) that can be supported in the file system? Explain your calculation.
參考解答:(a) 256 (b) $(12 + 2^8 + 2^{16} + 2^{24}) \times 2^{10} \text{ bytes}$
8. (5%) Consider a computer with a processor that operates at 4GHz ($4 \times 10^9$ cycles/second). When a network packet arrives, the network card interrupts the CPU, which then processes the packet. The cost of the following sum to 10000 cycles: a context switch to the interrupt handler, handling a packet, and the context switch out of the interrupt handler. A lot of other computers want to talk to this computer, and for a time, it receives 1000 packets per second. Assume one interrupt per packet. What is the total percentage of the processor’s cycles that are spent in interrupt-related code (meaning the context switching and packet handling)? Explain your answer briefly (for example, by showing your work).
參考解答:$\dfrac{1}{400} = 0.25\%$
9. (6%) A computer has 3 instruction classes. They are A, B and C. The A instruction class is 1 CPI (clock cycles per instruction), the B instruction is 2 CPI and the C instruction is 3 CPI. A program code has 5 millions of the A instruction class, 2 millions of the B instruction class and 3 millions of the C instruction class. Assume that the clock rate of the computer is 100 MHz. What is the execution time of the program code?
參考解答:0.18s
10. (2%) What is the decimal value of the 4-bit two’s complement binary number 1010?
參考解答:-6
11.
(a) (4%) A full adder has two 1-bit numbers $x_i, \, y_i,$ a carry-in bit $c_i,$ a sum bit $z_i$ and a carry-out bit $c_{i+1}.$ Write the equations of the sum bit $z_i$ in terms of $x_i, \, y_i,$ and $c_i.$
(b) (4%) A 4-bit carry-look-ahead adder has two 4-bit binary numbers $x_3x_2x_1x_0$ and $y_3y_2y_1y_0,$ a carry-in bit $c_0,$ the sum bits $z_3z_2z_1z_0$ and a carry-out bit $c_4.$ It can be formed from 4 stages, each of which is a full adder by replacing its output carry line $c_i$ by two carry generate signals $g_i$ and $p_i,$ where $0 \leq i \leq 3.$ Write the equation for the carry-out bit $c_4$ of the 4-bit carry-look-ahead adder in terms of $c_0, \, g_i \text{ and } p_i,$ where $0 \leq i \leq 3.$
參考解答:
(a) $z_i = x_i \bar{y_i} \bar{c_i} + \bar{x_i} y_i \bar{c_i} + \bar{x_i} \bar{y_i} c_i + x_iy_ic_i$
(b) $c_4 = g_3 + p_3g_2 + p_3p_2g_1 + p_3p_2p_1g_0 + p_3p_2p_1p_0c_0$
12. (11%) In a data cache, consider what the cache must do on a write miss.
(a) Describe two options for a write-through cache in response to a write miss.
(b) Describe a scenario that can benefit from each option listed in Part (a) above and briefly explain why.
(c) Describe the typical option for write-back cache in response to a write miss. Why are there fewer options than write-through caches?
參考解答:
(a) The first option is to allocate a block in the cache, called write allocate. The block is fetched from memory and then the appropriate portion of the block is overwritten. The second option is to update the portion of the block in memory but not put it in the cache, called no write allocate.
(b) The motivation for no write allocate is that sometimes programs write entire blocks of data, such as when the operating system zeros a page of memory. In such cases, the fetch associated with the initial write miss may be unnecessary.
(c) The typical option for write-back cache in response to a write miss is write allocate. Since in write-back cache, no block copy resides in memory, if only update the portion of the block in memory that will results in the updated data in cache block is inconsistent with the same block in memory.
13. (6%) If there is no mechanism for cache invalidation or for marking certain memory locations non-cacheable, the data cache and the DMA controller may not work properly together.
(a) If the cache is a write-back cache, can something go wrong if the DMA controller performs a read? What about a write?
(b) If the cache is a write-through cache, can something go wrong if the DMA controller performs a read? How about a write?
參考解答:
(a) Consider a read from I/O that the DMA unit places directly into memory in a write-back cache. If some of the locations into which the DMA writes are in the cache, the processor will receive the old value when it does a read. On the other hand, the DMA may write a value from memory to I/O when a newer value is in the cache, and the value has not been written back. That will result in the I/O gets the old value.
(b) In write-through cache, a read from I/O may also result in the processor receives the old value but a write to I/O doesn’t cause the I/O receives the old value since all the newer data in cache will update immediately to the memory block.
14. (8%) Given a basic five-stage pipelined MIPS CPU with comparator with the branch address computing done at the ID stage and the following sequence of instructions. We assume that branch predictor always predicts next instruction and for the execution of #40 beq the prediction is not taken.
36: lw $1, 8($4)
40: beq $1, $3, 7
44: and $12, $2, $5
...
72: lw $4, 50($7)
76: add $3, $4, $3
80: or $3, $2, $6
84: slt $3, $6, $3Please answer the following questions for execution from instruction #36 to #84.
(a) Assume there is no forwarding in this pipelined processor. How many NOPs are instead?
(b) Assume full forwarding. How many NOPs are inserted?
參考解答:
(a) 6 NOPs. 2 between (36, 40), 2 between (72, 76), and 2 between (80, 84).
(b) 3 NOPs. 2 between (34, 40), 1 between (72, 76).
15. (4%) True or False
(a) Like SMP, message-passing computers rely on locks for synchronization.
(b) Both multithreading and multicore rely on parallelism to get more efficiency from a chip.
(c) GPUs rely on graphics DRAM chips to reduce memory latency and thereby increase performance on graphics applications.
(d) Shared memory multiprocessors cannot take advantage of job-level parallelism.
參考解答:(a) F (b) T (c) F (d) F
16. (5%) What are the values (0 or 1) of control signals generated by the control in the following graph?
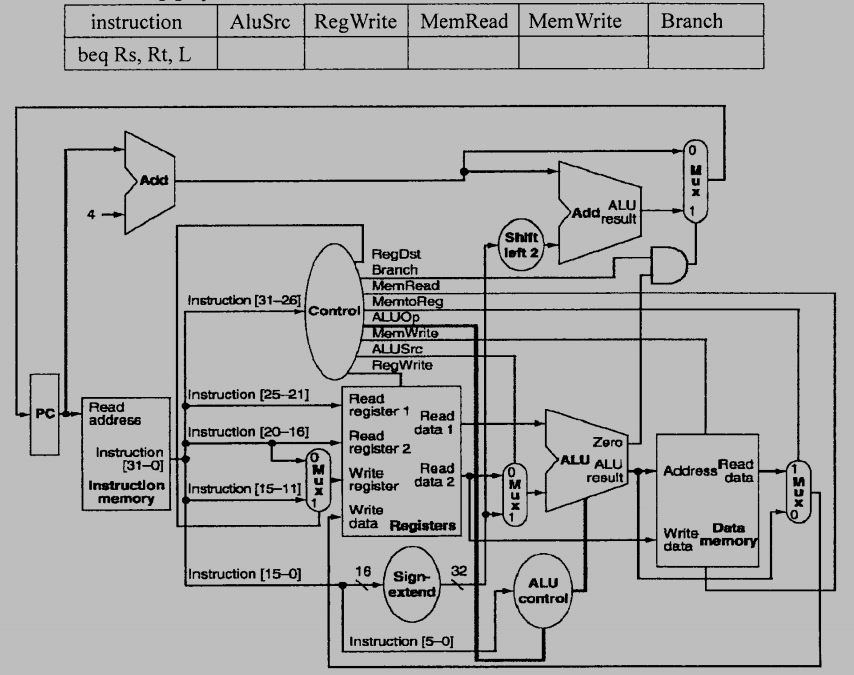
參考解答:0 / 0 / 0 / 0 / 1
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



maple
第8的(a)是因為register file 前半段讀後半段寫, 所以lw跟beq之間才只需要2個nop嗎
mt
對喔!先寫回再讀~
Ben
想請教 14.(a)(b)
我理解的題目意思是branch predictor對於beq $1, $3, 7的預測是不跳,再加上又問36~84這段指令,所以我推測實際上該beq $1, $3, 7是會跳的。
因此and $12, $2, $5會進到pipeline,而不管有沒有實作forwarding, 此指令都應該要被flush(插nop)才對。所以我覺得(a)(b)的答案都要再加上1個nop,分別是7,4。
不知道我的想法哪裡有誤?
mt
哈囉~這邊我的想法是We assume that branch predictor always predicts next instruction這句話代表branch predictor每次都100%的準確率猜對下一個指令(跳或不跳),所以這個情況下and是不會被flush掉的!