

1. (8%) For the following questions we assume that the pipeline contains 5 stages: IF, ID, EX, M, and W and each stage requires one clock cycle. A MIPS-like assembly is used in the representation.
(a) Explains the concept of forwarding in the pipeline design.
(b) Identify all of the data dependencies in the following code. Which dependencies are data hazards that will be resolved via forwarding?
ADD $s2, $s5, $s4
ADD $s4, $s2, $s5
SW $s5, 100($s2)
ADD $s3, $s2, $s4參考解答:
(a) Forwarding is a method of resolving a data hazard by retrieving the missing data element from internal buffers rather than waiting for it to arrive from programmer-visible registers or memory.
(b)
Data dependency: (1, 2), (1, 3), (1, 4), (2, 4)
Data hazard (resolved via forwarding): (1, 2), (1, 3), (2, 4)
2. (9%) Suppose out of order execution is adopted in a pipeline design. The figure below gives a generic pipeline architectures with out-of-order pipeline design.
(a) Explain the needed work in the reservation station and reorder buffer, respectively, in order to support out of order execution.
(b) In order to reduce power usage, we want to power off a floating point unit when it is no longer in used. The following code fragment uses a new instruction called Power-off to attempt to turn off floating point multiplier when it is no longer in used. To deal with out of order executions, what are the work needed for reservation station and reorder buffer to avoid the “Power-off@multiplier” instruction to be moved in front of the set of multiply instructions.
mul.d $f2, $f4, $f6
mul.d $f1, $f3, $f5
mul.d $f7, $f1, $f2
Power-Off @multiplier
/* Integer operations in the rest of the assembly code */
ADD $2, $5, $4
...
END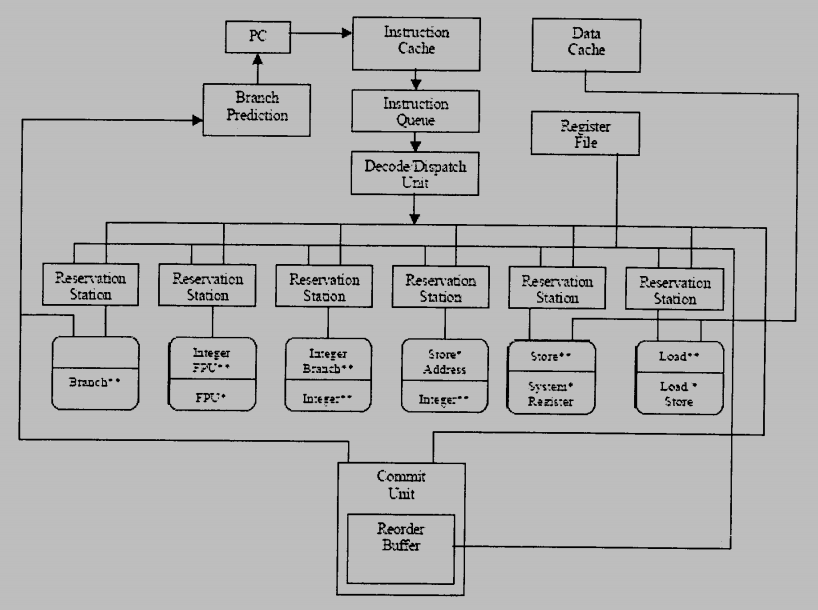
參考解答:
(a)
Reservation station is a buffer within a functional unit that holds the operands and the operation.
Reorder buffer is the buffer that holds results in a dynamically scheduled processor until it is safe to store the results to memory or a register.
(b) The reservation station of floating point multiplier has to check that there are no floating point multiplication instructions remained and the reorder buffer has to commit the Power-off@multiplier instruction after all floating point multiplication instructions.
3. (8%) A non-pipelined processor A has anaverage CPI (Clock Per Instruction) of 4 and has a clock rate of 40MHz.
(a) What is the MIPS (Million Instructions Per Second) rate of processor A?
(b) If an inproved successor, called processor B, of processor A is designed with four-stage pipeline and has the same clock rate, what is the maximum speedup of processor B as compared with processor A?
(c) What is the CPI value of processor B?
參考解答:(a) 10 (b) 4 (c) 1
4. (8%) Denote respectively $s_i$ and $c_i$ the Sum and CarryOut of a one-bit adder Adder($a_i,b_i$), where $a_i$ and $b_i$ are input.
(a) For a 16-bit addition, if we use the ripple adder, how many gate delay is required for generating $c_{16}$ after bits A, B, and $c_0$ are applied as input?
(b) If we use the carry-look-ahead adder, where the 16-bit adder is divided into four 4-bit adders. In each 4-bit adder there is a 4-bit carry-look-ahead circuit. Let $p_i = a_i + b_i$ and $g_i = a_i \times b_i$ and assume there is one gate delay for each $p_i$ and $g_i$ and two gate delays for each carry $c_4,c_8,c_{12},c_{16}$ and final three gate delay for $s_{15}.$ How many gate delay is required for generating $c_{16}$ after A, B, and $c_0$ are applied as input?
(c) Another way to apply look-ahead circuit is to add a second-level look-ahead circuit. With the second-level look-ahead circuit, how many gate delay is required for generating $c_{16}$ after A, B, and $c_0$ are applied as input?
參考解答:(a) 32 (b) 9 (c) 5
5. (10%) Please fill “?” with the answer of “up” or “down” in the following. For example, when associativity goes up, the access time goes up.
| Design change | Effect on miss rate | Possible effects |
| Associativity (up) | conflict miss (a?) | access time (up) |
| Cache size (down) | capacity miss (b?) | access time (c?) |
| Block size (down) | spatial locality (d?) | miss penalty (e?) |
參考解答:(a) down (b) up (c) down (d) down (e) down
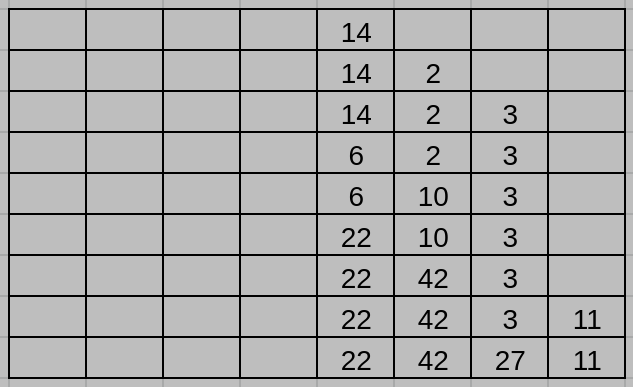
6. (7%) In 2-way cache, there are already 3 numbers in the sequence of 14, 2, 3 in the cache. The following table shows the time sequences when 14, 2, and 3 are inserted into the 2-way cache. Please insert 6 numbers after and show the time sequence using LRU. 6, 10, 22, 42, 11, 27.
參考解答:
7. (10%) Suppose that there are a number of processes, $P_1,P_2,…,$ in a computer. Their arrival times are denoted by $a_1,a_2,…;$ their CPU burst time are denoted by $b_1,b_2,….$ Processes are scheduled by the Shortest-Remaining-Time-First scheduling algorithm. Suppose that the context switching takes 0 second.
(a) Consider the case with 2 processes where $a_1 = 0, \, b_1 = 10, \, a_2 = 4, \text{ and } b_2 = 2.$ In this case, what is the total waiting time (over all the processes)? PS: Waiting time of a process is the sum of the periods spent waiting in the ready queue.
(b) Consider the case with n processes. For each process i, $a_i < a_{i+1} < a_i + b_i$ and $b_i < b_{i+1}.$ Write the total waiting time (over all the processes) in terms of $a_1,a_2,…,a_n \text{ and } b_1,b_2,…,b_n.$
參考解答:(a) 2 (b) 略
8. (10%) A process is a program in execution. A process can be further divided into a text section, data section, heap, and process stack. Consider the below program written in C.
#include <stdio.h>
#include <stdlib.h>
float float_array[10];
static double double_array[10];
int main(void)
{
int num;
scanf("%d", &num);
int *int_array = (int*) malloc(num * sizeof(int));
// Some lines are removed for space reason.
return 0;
}
void foo1(int n)
{
n = (n > 0) ? 1 : 0;
printf("%d", n);
}
void foo2()
{
static int count = 0;
count++;
printf("%d", count);
}Please fill in the following blanks with text, data, heap, or stack.
(a) The variable array “float_array” is stored in the _ section.
(b) The variable array “double_array” is stored in the _ section.
(c) The variable array “int_array” is stored in the _ section.
(d) The variable “n” is stored in the _ section.
(e) The variable “count” is stored in the _ section.
參考解答:(a) data (b) data (c) heap (d) stack (e) data
9. (6%)
(a) What is Inverted page table? Show its hardware and explain how it works to convert a logical address to a physical address.
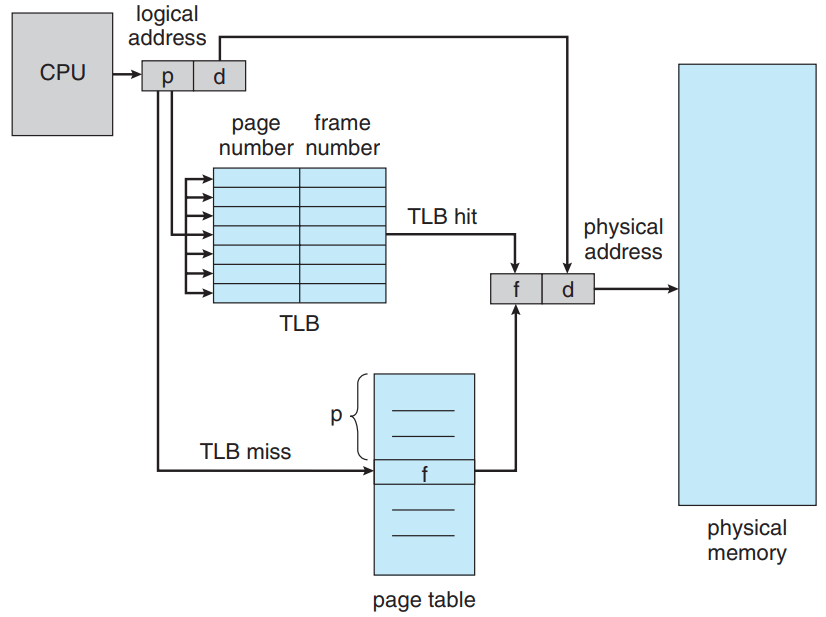
(b) Show the paging hardware with TLB (translation look-aside buffer), and explain how it works to convert a logical address to a physical address.
參考解答:
(a) Inverted Page Table is the global page table which is maintained by the Operating System for all the processes. In inverted page table, the number of entries is equal to the number of frames in the main memory. It can be used to overcome the drawbacks of page table.
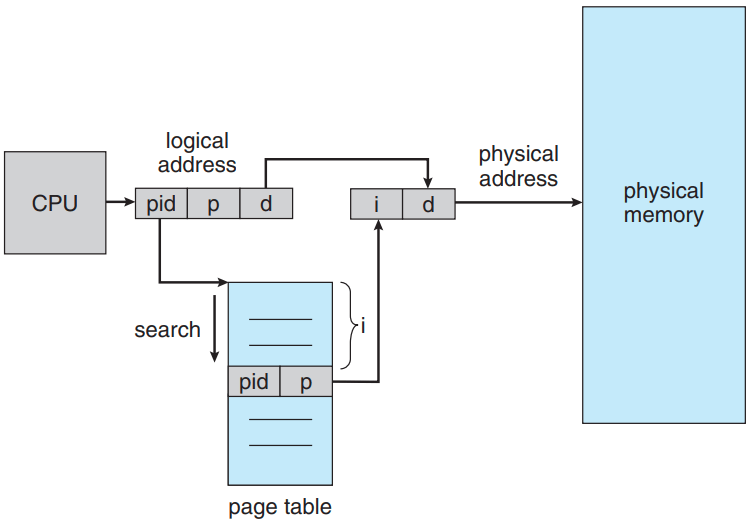
(b)
10. (9%)
(a) What is thrashing?
(b) What is working set (WS) concept?
(c) Explain how the WS concept could be used to solve the thrashing problem.
參考解答:
(a) If the process does not have the number of frames it needs to support pages in active use, it will quickly page-fault. At this point, it must replace some page. However, since all its pages are in active use, it must replace a page that will be needed again right away. Consequently, it quickly faults again, and again, and again, replacing pages that it must bring back in immediately. This high paging activity is called thrashing. A process is thrashing if it is spending more time paging than executing.
(b) Use the locality to predict the number of free frames needed in a period of time, and then reduce the possibility of thrashing.
(c) Use the working set to check the sum of frames needed for all running processes, if the number is higher than the physical frames number, we should decrease the degree of multiprogramming.
11. (6%) Consider the three disk allocation schemes below: “contiguous allocation”, “linked allocation” and “indexed allocation”. Which scheme will you choose if the file operations are mostly consisted of “append” and “truncate”. Explain your answer.
參考解答:I would choose “indexed allocation”, because it’s more easy to append and truncate data compared to “linked allocation”, and “contiguous allocation” need all data to be contiguous, so it’s not under consideration.
12. (9%) Explain why disk has worst I/O performance for random access, and give two solutions that can improve the random access performance of a disk.
參考解答:Because each access, we need to move the head to the trace of the sector we’re accessing, so if we access data randomly, the head seek time will be a problem. Improve methods: (1) Choose more suitable disk algorithm (2) Save or access files sequentially and on the same cylinder, so we can access multiple blocks of data without having to move the head.
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



發佈留言