

1. (3%) Consider a system running ten I/O-bound tasks and one CPU-bound task. Assume that the I/O-bound tasks issue an I/O operation once for every millisecond of CPU computing and that each I/O operation takes 10 milliseconds to complete. Also assume that the context switching overhead is 0.1 millisecond and that all processes are long-running tasks. What is the CPU utilization for a RR (Round-Robin) scheduler when the time quantum is 5 milliseconds?
參考解答:$\dfrac{1 \times 10 + 5 \times 1}{1.1 \times 10 + 5.1 \times 1} = \dfrac{15}{16.1} \approx 93.17\%$
2. (12%) Consider the following set of processes, with the length of the CPU-burst time given in milliseconds:
| Process | Burst Time | Priority |
|---|---|---|
| $P_1$ | 12 | 2 |
| $P_2$ | 8 | 1 |
| $P_3$ | 5 | 4 |
| $P_4$ | 10 | 5 |
| $P_5$ | 7 | 3 |
The processes are assumed to have arrived in the order of $P_1, \, P_2, \, P_3, \, P_4, \, P_5,$ all at time 0.
(a) Draw three Gantt charts illustrating the execution of these processes using the following scheduling algorithms: SJF (Shortest Job First), nonpreemptive priority (a smaller priority number implies a higher priority), and RR (quantum = 5 milliseconds).
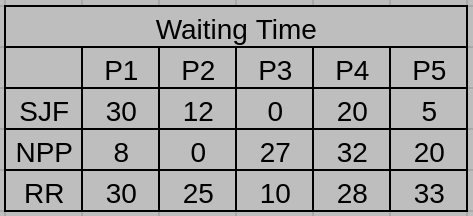
(b) What is the waiting time of each process for each of the scheduling algorithms in Part a?
參考解答:
(a)
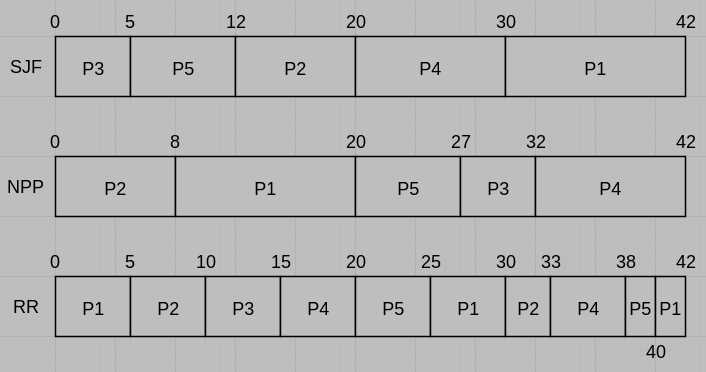
(b)
3. (10%) Consider the Banker’s algorithm for deadlock avoidance. The following is a snapshot of a system with four types of resources A, B, C, and D.
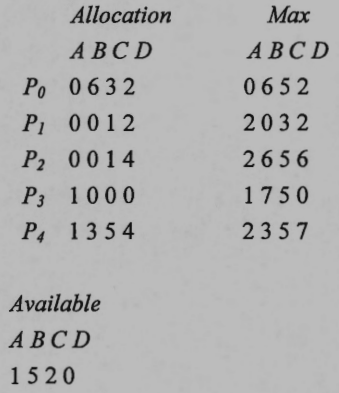
Allocation: An $n \times m$ matrix defines the number of resources of each type currently allocated to each process. If Allocation[i][j] equals k, then process $P_i$ is currently allocated k instances of resource type $R_j.$
Max: An $n \times m$ matrix defines the maximum demand of each process. If Max[i][j] equals k, then process $P_i$ may request at most k instances of resource type $R_j.$
Available: A vector of length m indicates the number of available resources of each type. If Available[j] equals k, then k instances of resouce type $R_j$ are available.
Suppose that the algorithm checks the process in the order of $P_0 , \, P_1, \, P_2, \, P_3, \, P_4.$ Give the number of available resources of each type after each iteration of the banker’s algorithm.
參考解答:
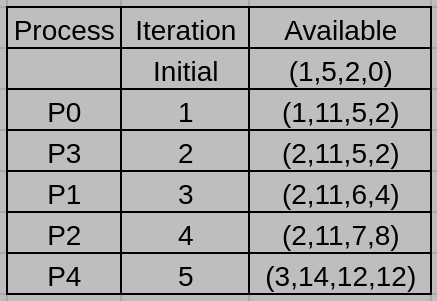
4. (11%) Consider a two-level page table memory management scheme that translates 22-bit virtual addresses to 16-bit physical addresses using page tables with 16-bit table entries. All the address formats are shown below:

(a) Explain what the purpose of dirty bit is.
(b) Give a logical reason why the designer might have made the virtual page number field 7 bits each for the inner and outer page tables.
(c) Consider a computer system that uses a TLB (Transition Lookaside Buffer) with only 2 entries with memory access time 200 nanoseconds and TLB search time 10 nanoseconds. What is the average effective memory access time for a process that is just context switched to access the sequence of hexadecimal virtual memory addresses: 22A956, 22AD76, 22ADFF, 22AF56, 22A958, 22AF58?
(d) Consider the case of an address translation from a virtual address 22AF58 to a physical address 7B58. Assume that we know the base address for the inner page table used in this translation is at the physical address location: A700. Which entry of the outer table is used for this address translation? What is the physical page number stored in that outer table entry? Which entry of the inner table is used for this address translation? What is the physical page number stored in that inner table entry?
參考解答:
(a) The purpose of dirty bit is to check whether the page has been modified or not. During page replacement, if the victim page is not modified, we don’t have to write it back to the disk, and reduce the I/O time.
(b) Because we don’t want the page table take more than one page size, also方便page table之swap in/out.
(c) $\dfrac{860}{6} \approx 143.33 \text{ ns}$
(d) 69, A7, 47, 7B.
5. (8%) Answer the following questions related to I/O methods.
(a) Compare I/O based on polling with interrupt-driven I/O. In what situation would you favor one technique over the other?
(b) Use an example to illustrate the steps of DMA (Direct Memory Access) I/O. Explain why DMA can improve overall system performance.
參考解答:
(a) If I/O process time is less than Interrupt service process time, polling I/O is better, if not, then interrupt-driven I/O is better.
(b)
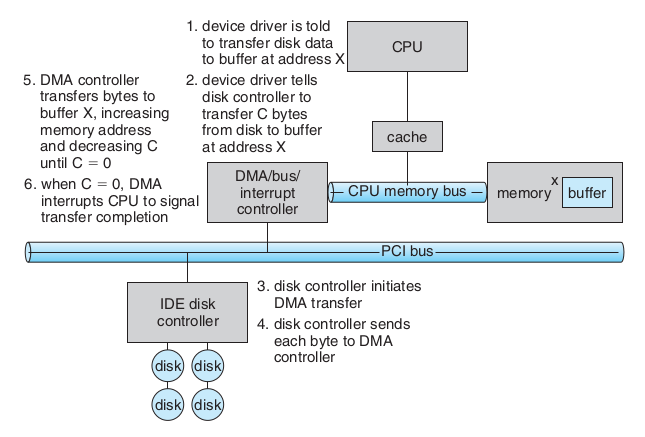
DMA負責I/O-Deivce and memory之間的data transfer, cpu無須介入。
6. (6%) Which of contiguous, linked, indexed file allocation method would you use in the following scenario and why?
(a) A swap space manager that stores pages in a limited amount of disk space.
(b) A database that serves record insertion, deletion, and search operations.
(c) A logging system that periodically appends new messages to log files.
參考解答:(a) Contiguous (b) Indexed (c) Linked
7. (12%) In computer architectures, an operation can have several instructions for different addressing modes. For instance, Figure 1 shows four Add instructions of different addressing modes.

(a) Explain when to use each instruction from the high level programming language aspect.
(b) What are the advantages or disadvantages of supporting different addressing modes for the same operation in the instruction set design?
(c) Why do all the instructions in Figure 1 have at least one addend stored in registers? What would be the problems if an architecture has an instruction like
Add (R1), (R2)which performs Mem[Regs[R1]] $\gets$ Mem[Regs[R1]] + Mem[Regs[R2]]?
參考解答:
(a)

(b) Advantages: More addressing modes given the programming flexibility and versatility to the user. Disadvantages: More addressing modes enlarge the instruction set and complex the specification; finally slow down the machine.
(c) Register is faster than memory. And have one addend stored in register can reduce memory traffic. The two operands in the instruction “Add (R1), (R2)” come from the memory and the addition result is also write to memory. This will result in very high memory traffic and create memory bottleneck.
8. (13%) Pipeline is often used in computer architecture to accelerate the system performance. However, its effectiveness is influenced by many factors.
(a) What are pipeline hazards? Explain what three major types of pipeline hazards are.
(b) The frequency of branches of a program and their penalties for predicted taken/untaken are summarized in the following table. Suppose that a branch predictor can successfully predict 80% of a conditional branch taken or untaken (which means if a conditional branch is taken, the predictor has 80% to predict taken, and 20% to predict untaken; and if a branch is untaken, the predictor has 80% to predict untaken, and 20% to predict taken). Suppose that the ideal CPI (Cycle Per Instruction) of the pipeline processor without any branches is 1. What is the effective CPI of the program with this branch predictor?

(c) The early architecture design usually has a very long pipeline. For instance, Intel Prescott (2004) has 31 pipeline stages. But recent architectures have relatively short pipelines. For example, Intel Kaby Lake (2016) has only 14 stages. Explain the possible reasons of this trend of architecture design.
參考解答:
(a)
Pipeline hazard: 管線無法在下一個clock執行下一個指令的狀況。
Structural hazards: 硬體資源不夠多,而導致在同一時間內要執行多個指令卻無法執行。
Data hazards: 管線中某一些指令需要用到前面指令(還在管線中)尚未產生的結果(資料相依),也就是執行的指令所需的資料還無法獲得。
Control hazards: 當分支指令尚未決定是否分支至其他指令執行時,後續指令便已經進入管線中,若分支發生則指令執行順序便會發生錯誤。控制危障的產生是由管線中的分支指令,及其他會改變PC的指令所引發的,因此又稱為branch hazards。
(b) $1 + 0.05 \times 2 + 0.05 \times 0.8 \times 2 + 0.05 \times 0.2 \times 4 + 0.1 \times 0.2 \times 3 = 1.28$
(c)
1. Longer pipeline increases clock rate but requires more power consumption.
2. Longer pipeline has smaller IPC (instruction per cycle).
3. Longer pipeline increases implementation complexity as well as cost.
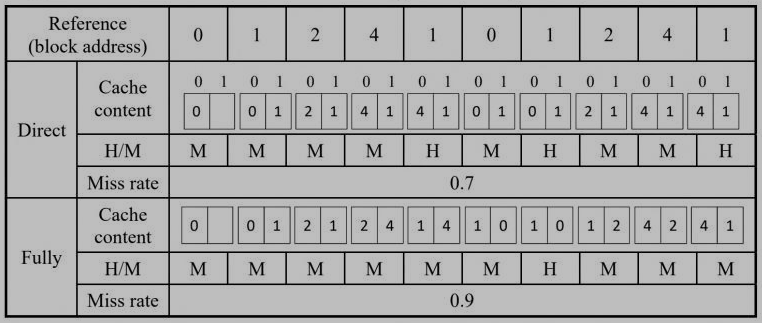
9. (6%) In general, a fully associative cache is better than a direct-mapped cache in terms of miss rate. However, it is not always the case for a cache, especially for a small cache. Give an example with 10 times memory references and use it to demonstrate that a direct-mapped cache outperforms a fully associative cache in terms of miss rate in detail under the replacement policy, LRU (Least Recently Used).
參考解答:
Suppose there are 2 blocks in both direct-mapped and fully associative caches
10. (14%) Given a unified cache consisting of instruction cache and data cache with NO write-buffer in a memory system. It uses the write through mechanism when a write-miss occurs. Given the following measurements:
- The base CPI with a perfect memory system = 1.5
- The miss rate = 5%
- The memory latency = 100 cycles
- The transfer rate = 4 bytes/clock cycle
- 30% of the instructions are data transfer instructions
- The size of a block = 32 bytes
(a) Explain “write-buffer”.
(b) Explain “write through”.
(c) Determine the effective CPI for this memory system without considering the TLB.
參考解答:
(a) A write buffer stores the data while it is waiting to be written to memory. After writing the data into the cache and into the write buffer, the processor can continue execution.
(b) A scheme in which writes always update both the cache and the memory, ensuring that data is always consistent between the two.
(c) $1.5 + 1 \times 0.05 \times 108 + 0.3 \times 0.05 \times 108 = 8.52$
11. (5%) For a typical disk without considering queuing delay, the average seek time is 5 milliseconds, and the transfer rate is 2M-bytes per second. The disk rotates at 600 RPM (Revolution Per Minute), and the controller overhead is 0.5 millisecond. Determine the average time to read a 1792-bytes sector.
參考解答:$5 \text{ ms } + 50 \text{ ms } + 0.896 \text{ ms } + 0.5 \text{ ms } = 56.396 \text{ ms}$
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



yummy
想請問第十題的c,209是怎麼來的?
mt
209是write miss的penalty = $100 + \dfrac{32}{4} + \dfrac{4}{4} + 100$ = 209,$\dfrac{4}{4}$是因為write through mechanism,表示會多寫一個word的data到cache~
yummy
謝謝,想再請問會有兩次 memory latency 是因為沒有 write buffer 的緣故嗎
yummy
啊,應該是一次讀回 cache 一次更新寫到 memory?
mt
對喔~你說的沒錯!
jojo
想請問第十題的c,後面0.3×0.05×209的部分有考慮read miss嗎 如果考慮進去且假設read write miss機率一樣是不是要變成0.3×(0.025×108+0.025×209)? 至於前面1×0.05×108是因為
只要考慮read miss是因為沒有write的問題 不知道我有沒有理解錯誤? 然後如果write hit也是用write through的話要另外算write through的cost嗎?
mt
這題的話是cache read miss跟cache write miss分開討論的,前面是cache read miss的penalty,後面就是cache write miss的penalty,當write miss發生的時候cache controller會去memory搬一個block到cache然後再將一個word的data寫入cache及memory,不用另外討論read miss的問題!然後因為是在算額外增加的penalty,應該是不用管write hit或read hit的,希望有回答到你的問題~
jojo
大概了解你的意思了 不過若是read write miss分開看的話前面1×0.05×108計算read miss的部分似乎只有包含instruction的read miss,題目說有30%是data instruction的部分(需要讀寫data),所以意思是直接假設data沒有read miss的問題只有write miss嗎?
mt
我後來想了一下,這邊的write through應該是搭配no write allocate,這樣write miss的時候不用寫到cache而是直接寫回memory,這樣的話write miss penalty的部分應該會跟read miss penalty一樣是108,然後答案的部分就要改成$1.5 + 1 \times 0.05 \times 108 + 0.3 \times 0.05 \times 108 = 8.52$。
補充:如果用我原本算的209(write allocate)的話會沒辦法算,因為題目沒有說這30%的data transfer instructions裡面write跟read的比例,所以兩個的penalty要一樣才能算!
jojo
了解 感謝