

1. [20%] Please briefly show and discuss the architectures and pipelines for CPU and GPU.
參考解答:
CPU pipeline is a technique for implementing instruction-level-parallelism within a single processor. It attempts to keep every part of the processor busy with some instruction by dividing incoming instructions into a series of sequential steps performed by different processor units with different parts of instructions processed in parallel.
GPU pipeline is a conceptual model that describes what steps a graphics system needs to perform to render a 3D scene to a 2D screen. Once a 3D model has been created, for instance in a video game or any other 3D computer animation, the graphics pipeline is the process of turning that 3D model into what the computer displays.
2. [10%] What are (a) heterogeneous computing and (b) data parallel computing?
參考解答:
(a) Heterogeneous computing refers to systems that use more than one kind of processor or cores. These systems gain performance or energy efficiency not just by adding the same type of processors, but by adding dissimilar coprocessors, usually incorporating specialized processing capabilities to handle particular tasks.
(b) Data parallel computing is a programming paradigm in which the same analysis code is applied to different data elements.
3. [20%] Consider two matrices $A$ and $B,$ where $A$ and $B$ are by $M \times N$ and $N \times P,$ respectively. Please illustrate a C program (extended by some GPU programming framework that you are familiar with) to perform the matrix multiplication of $A$ and $B,$ resulting in a matrix $C$ by $M \times P,$ with CPU accelerated by GPU.
參考解答:略
4. [20%] Synchronization is an important mechanism to control concurrent access to critical sections by multiple process/threads. Please answer the following questions based on the semaphore-based software functions listed below, where the functions can be used by multiple threads to make sure that no thread could read or write the shared data while another thread is writing to it.
semaphore wmut=1;
semaphore rmut=1;
rcount=0;
void writer() {
wait(wmut);
signal(wmut);
}
void reader() {
wait(rmut);
rcount+=1;
if (rcount == 1)
wait(wmut);
signal(rmut);
// Read things from the shared data.
wait(rmut);
rcount-=1;
if (rcount == 0)
signal(wmut);
signal(rmut);
}(1) Is the above pseudo code representing the optimal solution to the readers-writer problem? Why?
(2) Assume that there are three threads, a reader R1, a writer W1, and a reader R2, about to entering the critical sections as the above order. What is the actual sequence of the three threads entering the critical sections?
(3) What is the spacial hardware instruction(s) used to implement the semaphores?
(4) Sometimes, some embedded platforms may not have the special hardware instruction(s) support. In this case, what kind of the software implementation can be used to ensure that the lock operation, such as wait() and signal() semaphore operations, are performed atomically?
參考解答:
(1) No, this is the first readers-writers problem, which treats the readers better than the writers and may cause the writers wait forever.
(2) $R1 \to R2 \to W1$
(3) Test-and-set, Swap.
(4) Use algorithms that ensure mutual exclusion, progressive, and bounded-waiting like Perterson’s algorithm, Bakery’s algorithm.
5. [30%] File system have software caches to accelerate accesses to the frequently used data. Please answer the following question related to file system designs.
(1) What kinds of caches, besides processor caches, may be used while performing file data reads from the disk into a user-space application? In what situation are the file data writes not being buffered in the above software caches?
(2) What is the name of the virtual-memory technique used to cache both process pages and file contents? On such a system, what will happen if processes are reading large files and storing the file data into their heap memory?
(3) What is the situation used to describe the file data being buffered twice in different caches?
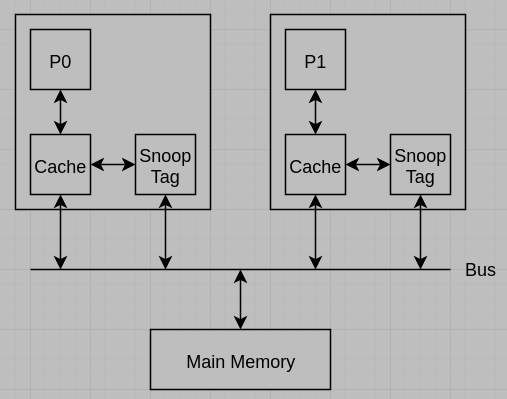
(4) What is the technique that is used to avoid the file data being cached twice? Please also draw the block diagram for the file I/O using the technique.
參考解答:
(1) Page cache (software)
(2) Paging
(3) Cache coherency
(4) Snooping,
試題(pdf):連結
有任何問題,或想要完整解釋的,歡迎在下方留言唷!



發佈留言